[KOR][30]SIGGRAPH-2025-Advances--STRAND-BASED-HAI
https://m.youtube.com/watch?v=jSE1XXBEK-w

안녕하세요, 저는 MachineGames의 Sergei Kulikov입니다. 본 강연은 Indiana Jones and the Great Circle에서의 strand-based hair에 관한 것입니다.

향후 40분 동안의 발표 안건은 다음과 같습니다. 먼저, Strand hair 디자인 시 목표와 요구사항을 살펴보겠습니다. 최종적으로 구현된 시스템과 각 구성 요소의 연계성에 대해 간략히 개괄하겠습니다. 이어서 시스템의 주요 세 부분인 rasterization, shading, composition을 심층적으로 다루겠습니다. 해당 시스템들의 알고리즘 및 성능 최적화 방안을 논의할 예정입니다. 오늘 시간 관계상 hair simulation과 hair path tracing은 다루지 못하며, 앞서 언급한 부분들에 집중하겠습니다.
발표에 앞서, Strand hair 시스템이 프로젝트 개발 전반에 걸쳐 대규모 협업의 결과물임을 강조하고 싶습니다. 프로토타이핑, 개발, 출시까지 기여해주신 모든 분들께 진심으로 감사드립니다. 특히, 저희 작업의 근간이 되는 훌륭한 엔진을 제공해주신 software engine 팀과, 소중한 의견과 훌륭한 콘텐츠를 만들어주신 character art 팀께도 감사드립니다. 또한, Strandhair 개발의 초석을 다지고 초기 구현을 맡아주신 Michael Wynn님과 hair simulation 분야에서 훌륭한 성과를 보여주신 George Luna님께 특별히 감사드립니다.
이제 발표를 시작하겠습니다. Indiana Jones and the Great Circle에서 Strandhair에 집중하기로 결정한 이유는 무엇일까요? 본 게임은 1인칭 시점으로 플레이어가 인디아나 존스의 역할을 맡아 전 세계를 무대로 장대한 모험을 떠나는 작품입니다. 캐릭터에 대한 깊이 있는 묘사가 중요한 스토리 중심의 게임이며, 총 4시간 분량의 컷씬이 포함되어 있습니다. 또한, 1인칭 시점은 플레이어가 적의 얼굴을 가까이서 보게 됨을 의미합니다. 이러한 게임에서는 캐릭터의 외형을 최대한 훌륭하게 구현하는 것이 필수적입니다.
아티스트를 위한 hair 제작 워크플로우 간소화 또한 중요한 고려 사항이었습니다. 게임 내 다수의 캐릭터를 위해 아티스트들이 창의적인 작업에 더욱 집중할 수 있도록 하고자 했습니다. 더불어 여러 요구사항이 있었습니다. 첫째, 모든 대상 플랫폼에서 반응성과 부드러움을 갖춘 60fps 게임플레이 목표를 항상 엄격하게 유지했습니다. 이는 명확한 목표였으며, 설계된 모든 시스템은 60fps로 구동되어야 했습니다.
GPU 예산은 최소 사양에서 최대 12명 정도의 캐릭터가 화면에 등장하고 일부는 카메라에 근접하는 최악의 시나리오를 기준으로, simulation과 rendering에 합쳐 2ms로 추정되었습니다. 물론, 더 단순한 시나리오에서는 hair 렌더링 속도를 이보다 빠르게 달성하는 것을 목표로 합니다. 아티스트에게 추가적인 작업을 부여하는 것을 피하고자 했습니다. 각 hair 에셋에 대해 별도의 버전을 두 개씩 제작하는 것을 원치 않았기에, 시스템은 어디서든 사용될 수 있도록 빠르고 견고해야 했습니다. 결과적으로, 동물 등에 사용된 일부 에셋을 제외하고는 hair cards를 사용하는 경우는 거의 없었습니다.
이 두 가지 요구사항이 충족된다면, 최대한의 시각적 품질을 확보하고자 했습니다. 물리적 정확성을 추구하지만, 이를 벗어나 성능 향상을 크게 얻을 수 있다면 그러한 방식을 택할 것입니다. hair 제작 워크플로우가 어떻게 진행되었는지 간략히 설명해 드리겠습니다. hair cards를 사용할 경우, 먼저 strand로부터 hair card atlas를 제작해야 합니다. 이후 카드를 배치하고 조형하여 원하는 스타일을 구현합니다. 그런 다음 mesh normal을 조정하고 모든 것을 엔진으로 내보낸 후, 엔진 내에서 material을 조정해야 합니다. 반복 작업 시에는 종종 몇 단계를 다시 수행해야 하며, 대부분의 단계는 매우 기술적이고 시간이 많이 소요됩니다.
하지만 strand를 직접 사용할 경우, 파이프라인에서 두 단계를 생략할 수 있습니다. 이제 mesh normal을 다룰 필요가 없으며, 카드를 제작할 필요도 없습니다. 오직 hair spline을 직접 스타일링하기만 하면 됩니다. 이를 위해 Xgen Interactive Groom을 사용했지만, Houdini나 Xgen 등 원하는 어떤 툴을 사용하셔도 무방하며, export 후 hair material을 조정하면 됩니다. 각 반복 작업이 훨씬 빨라집니다. 이러한 워크플로우 간의 차이가 크기 때문에, 하나의 hair 버전에서 다른 버전으로 자동 변환하는 것은 불가능합니다. 이것이 두 개의 hair 버전을 만들지 않으려는 이유입니다.

게임 내 캐릭터들의 머리카락과 수염, 그리고 얼굴 털은 모두 strands를 사용하여 구현되었습니다. 헤어 카드(hair cards)를 사용한 캐릭터는 게임 전체에서 두 구의 시체에 불과할 정도로 strands 활용도가 높습니다.
의상의 일부 퍼(fur) 디테일 역시 strands로 표현되었습니다. 예를 들어, 인디아나 존스의 겨울 재킷에 있는 모자와 색상 부분에 사용되었습니다.
동물 털에도 strands를 적용하려 시도했으며, 일부 동물(거미, 원숭이 등)에 성공적으로 사용했습니다. 다만, 게임 내 강아지들은 여전히 헤어 카드를 사용하고 있습니다. 모든 동물에게 strands를 적용하지 못한 몇 가지 이슈가 있었으며, 이에 대해서는 추후 더 자세히 다룰 예정입니다.
손가락과 손등의 털은 게임 막바지에 추가되었으나, 결과물에 매우 만족하고 있습니다.
이어지는 내용은 hair pipeline에 대한 설명이며, 그 전에 엔진에 대한 배경 지식을 공유하겠습니다. 저희 엔진은 it tech 7을 기반으로 하며, 렌더링 코드 상당 부분을 공유합니다. 직접 조명 계산에는 clustered forward rendering을 사용하지만, Diffuse GI와 같은 일부 불투명 패스(opaque passes)는 deferred 방식으로 처리됩니다.
GPU 메모리는 게임 플레이 중에 동적으로 할당되지 않고 사전에 모두 할당됩니다. 모든 셰이더는 그래픽 엔지니어들이 직접 코드를 작성하여 최대한의 제어와 성능을 확보했습니다. 또한, 엔진은 sync compute를 적극적으로 활용하며, 프레임의 상당 부분이 SamadSync 작업으로 이루어집니다.
단일 렌더링 프레임의 일반적인 개요를 살펴보겠습니다. 각 세그먼트의 너비는 실제 GPU 타이밍을 나타내기보다, 이웃 큐(neighbor queue) 작업과의 관계 속에서 프레임 내에서의 위치를 나타냅니다.
본 발표에서는 프레임을 세 가지 큰 부분으로 나누어 이해하는 것이 중요합니다. 첫째, GPU scene gather, shadows, ray tracing, BVH constructions 등 일반적인 패스(common passes)입니다. 둘째, 불투명 픽셀(opaque pixels)과 혼합 지오메트리 렌더링(blended geometry rendering)을 위한 조명 패스(lighting passes)입니다.
혼합 지오메트리 작업을 최대한 초기에 진행하고 일부를 미리 완료함으로써 scene compute를 활용하고자 합니다.
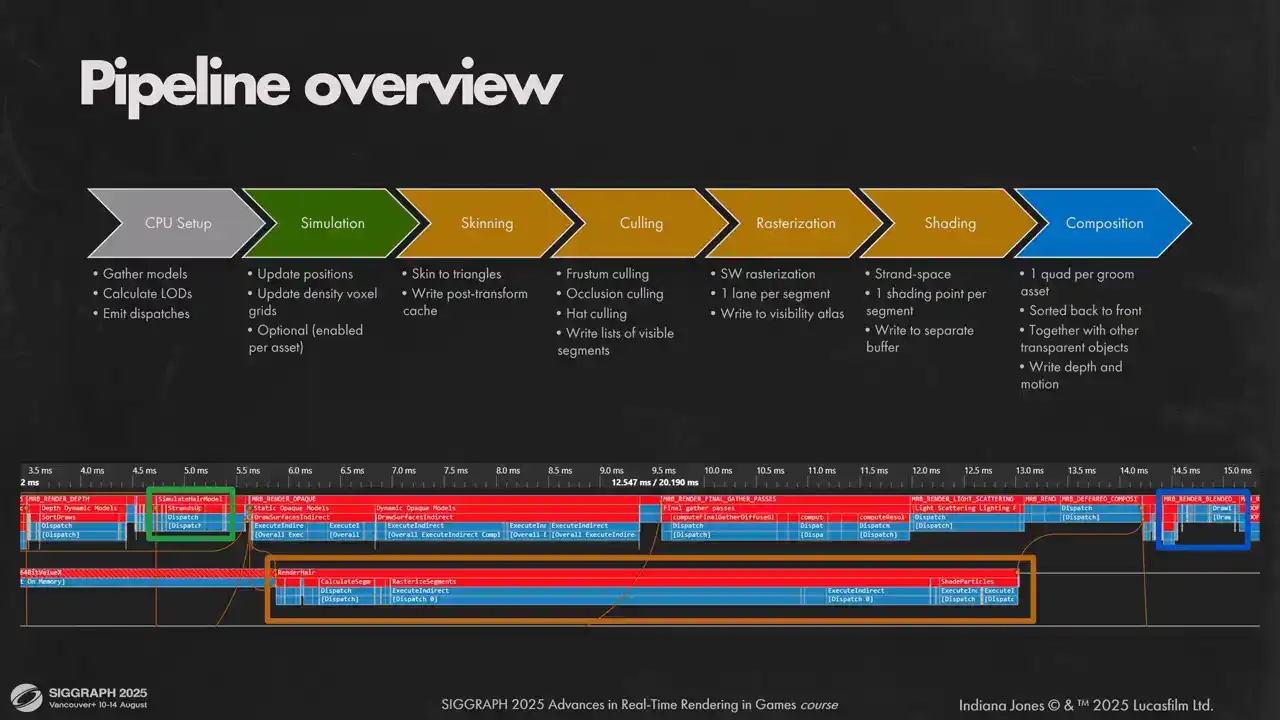
메인 큐(main queue)는 불투명(opaque) 픽셀을 렌더링합니다. 이제 헤어 렌더링 파이프라인을 살펴보겠습니다. CPU에서는 뷰포트 내의 모든 헤어 모델을 수집하고, 적절한 LED(Light Emitting Diode)를 계산하여 디스패치(dispatch)를 생성하는 간단한 설정 작업이 수행됩니다. GPU 측에서는 파이프라인을 세 부분으로 나눕니다.
첫 번째는 시뮬레이션(simulation)입니다. 시뮬레이션은 헤어 오브젝트별로 아티스트가 설정할 수 있습니다. 메인 그래픽스 큐(main graphics queue)에서 수행하는 이유는 불투명 라이팅 패스(opaque lighting passes) 시작 전에 헤어 시뮬레이션을 완료하기 위함입니다.
두 번째는 헤어를 레이어드 비저빌리티 버퍼(layered visibility buffer)에 렌더링하고 버텍스 셰이딩(vertex shading)을 수행하는 단계입니다. 이는 씬 컴퓨트(scene compute)에서 수행되며, 포워드 라이팅 패스(forward lighting pass) 및 디퓨즈 GI(diffuse GI)와 계산을 오버랩(overlap) 시킵니다. 이를 통해 GPU의 부하를 더욱 균일하게 만들 수 있습니다. 헤어 작업량은 예측 가능하고 균일하여 GPU 활용률의 공백을 효과적으로 채웁니다.
마지막 세 번째는 렌더링된 헤어를 화면에 합성(compose)하는 작업입니다. 헤어는 게임 내의 다른 투명(transparent) 지오메트리(geometry)와 동일하게 취급되며, 다른 지오메트리와 동일한 경로로 뒤에서 앞으로(back to front) 렌더링됩니다. 슬라이드 하단에는 전체 프레임과의 통합 방식을 확인할 수 있습니다. AsyncCompute 패스의 긴 시간은 실제 작업량이 훨씬 적기 때문이며, 이는 그래픽스 큐의 공백을 채우는 역할을 합니다.
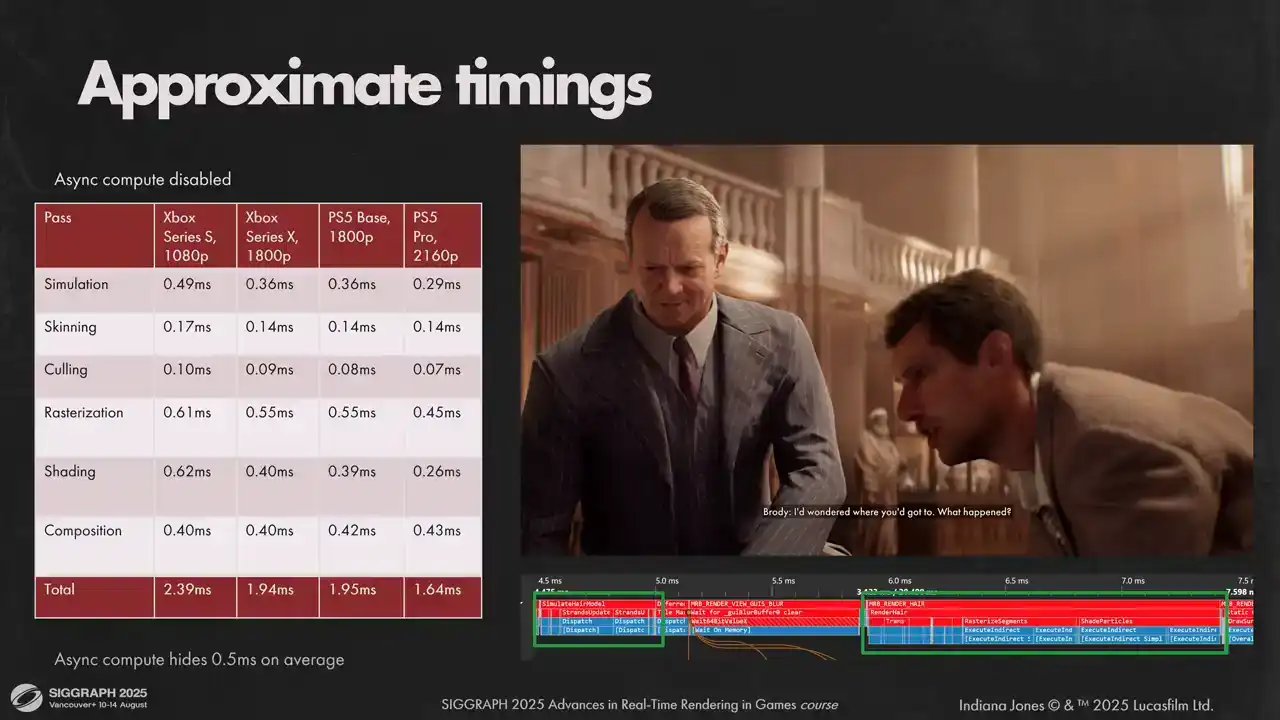
Async Compute를 비활성화할 경우, 평균적인 샷에서 화면에 표시된 수치를 얻게 됩니다. Sirius S의 경우 예산을 약간 초과하지만, Sync Compute를 활성화하여 측정하면 약 0.5밀리초를 회수하여 예측치에 부합합니다. 다른 하드웨어에서는 각 패스의 타이밍이 다소 다르지만, 합산하면 거의 동일한 수치가 나옵니다.
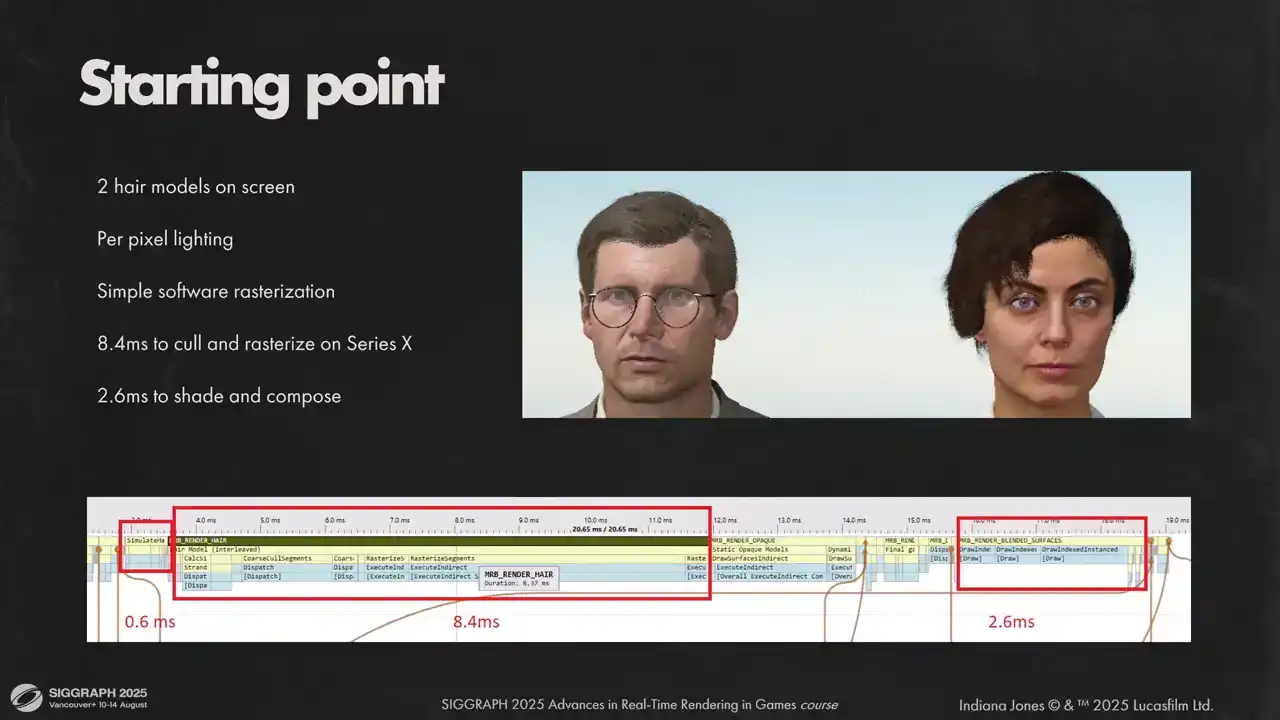
이것은 저희가 처음으로 머리카락 시스템의 성능을 측정한 결과입니다. 피부에 머리카락 그림자가 생기는 것을 제외하고는 대부분의 시각적 특징은 이미 구현되어 있었습니다. 그러나 보시다시피, 프레임 예산 내에서 이를 구현하기까지는 아직 갈 길이 멀었습니다.

먼저, 각 hair model의 Level of Detail(LOD)을 파악하는 것이 중요합니다. 별도의 LOD 모델을 사용하지 않고, 일반적인 방법인 strand order randomization을 적용합니다. 이를 통해 strand buffer의 일부만 사용하고 각 strand의 thickness를 비례적으로 조절하면 hair shape은 동일하게 유지됩니다. 따라서 계산해야 할 것은 각 model별 strand number뿐입니다.
이 작업은 세 단계로 진행됩니다. 첫째, model loading 시 quality settings에 따라 최대 strand 수를 제한합니다. 작은 hair model은 렌더링 시간에 미치는 영향이 적고, strand 수를 줄이면 그 변화가 더 잘 보이기 때문에 줄이지 않습니다.
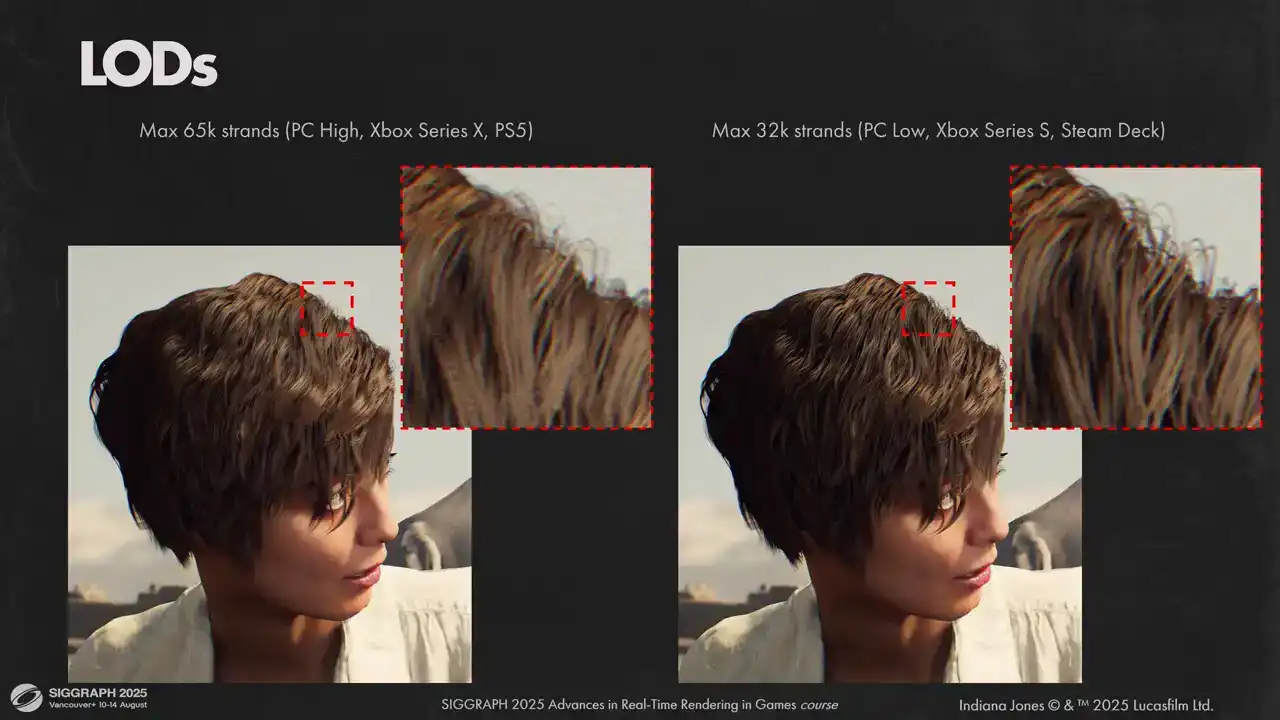
여기에서는 모델 내 최대 스트랜드(strands) 개수에 대한 두 가지 다른 옵션을 보실 수 있습니다. 왼쪽은 65,000개의 스트랜드를 사용한 최고 품질 설정이며, 오른쪽은 성능이 낮은 하드웨어에서 사용하는 최저 품질 설정입니다. 보시는 바와 같이 시각적 결과는 비슷하지만, 낮은 품질 버전이 더 어둡습니다. 이는 셀프 섀도잉(self-shadowing) 처리 방식과 관련이 있으며, 이에 대해서는 나중에 좀 더 자세히 살펴보겠습니다.

각 프레임마다 헤어 모델별 스크린 영역을 계산하고, 보이는 영역당 렌더링될 세그먼트 수를 일정하게 유지하기 위해 스트랜드 수를 조절합니다. 모든 플랫폼에서 64x64 픽셀 타일당 최대 2000개의 세그먼트를 사용하는데, 이는 시각적 결과와 성능 면에서 모두 만족스럽기 때문입니다.
모델별 초기 로드를 계산한 후, 렌더링되는 모든 모델의 총 세그먼트 수를 확인하고 200만 개로 제한합니다. 이 제한을 초과하면 모든 모델의 스트랜드 수를 비례적으로 줄여 한계 내로 맞춥니다. 이는 모든 정점(vertex) 계산 및 메모리에 대한 상한선을 설정합니다.
추가적으로, 정점 계산량을 더 줄이기 위해 모델별로 거리에 따라 일정 간격으로 헤어 정점을 건너뛸 수 있습니다. 이는 셰이딩되는 정점 수를 절반으로 줄이지만, ...
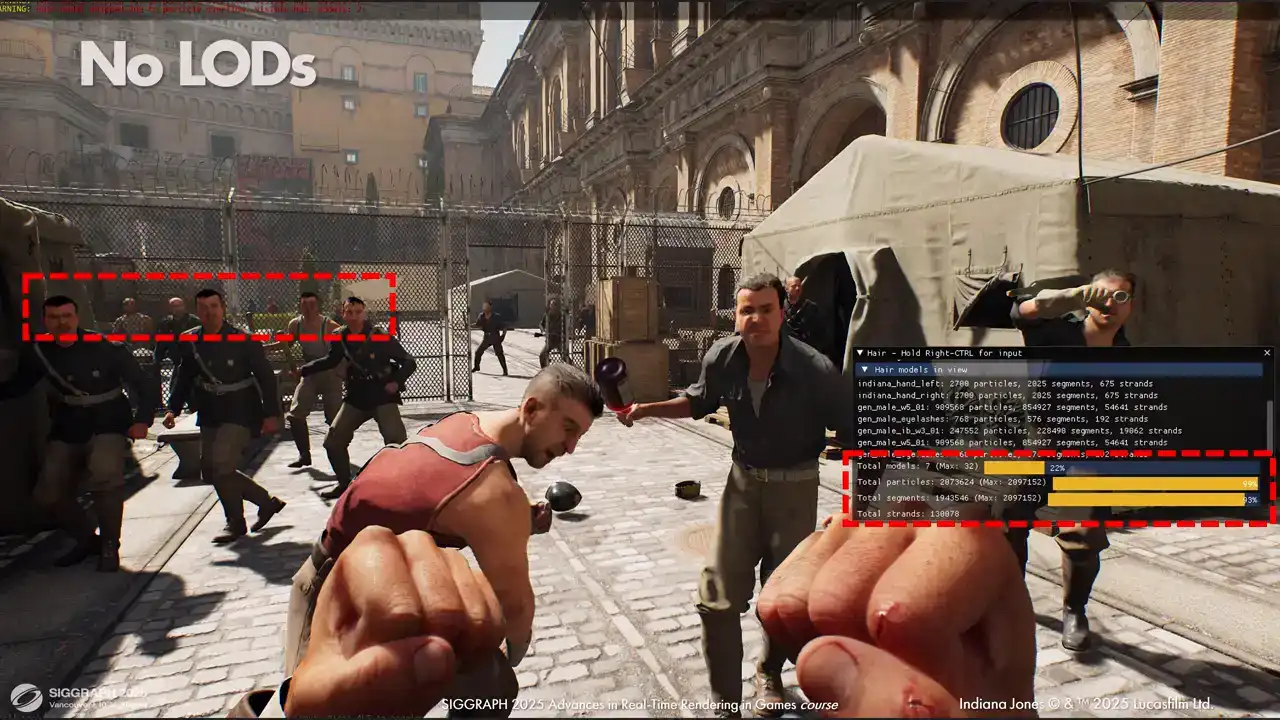
sterilization cost는 픽셀 수에 비례하여 증가하며, segment 자체의 개수와는 무관합니다. 이는 화면 내에서 다수의 캐릭터와 풍성한 헤어스타일을 유지하는 데 어떻게 도움이 되는지 보여줍니다. Elodie가 없을 경우, 프레임당 7개의 헤어 모델만 배치할 수 있으며, 그중 두 개는 손에 가려져 있습니다. 보시다시피, 뒤쪽의 다른 캐릭터들은 아무것도 렌더링되지 않아, 복잡한 적 진영에 진입하는 게임에서 문제가 발생합니다. 하지만 LOD(Level of Detail)를 사용하면 모든 캐릭터를 배치하고 우수한 시각적 품질을 유지할 수 있으며, 여전히 동일한 수의 segment를 렌더링합니다.

시뮬레이션은 Müller의 "Fast Simulation of Inextensible Hair and Fur" 논문을 기반으로 하였습니다. 모든 스트랜드와 각 스트랜드 내 모든 파티클을 시뮬레이션하며, 이는 헤드 스키닝 이전에 수행됩니다. 따라서 시뮬레이션 시점에서는 메인 헤드 조인트의 움직임만 고려합니다. 헤드와의 충돌은 미리 SDF(Signed Distance Field)로 변환된 헤드 지오메트리를 활용하여 처리합니다. 헤어스타일 길이가 길지 않아 헤드-바디 충돌 처리는 별도로 수행하지 않습니다.
시뮬레이션 완료 후, 각 헤어 버텍스의 로컬 포지션과 속도 정보를 다음 패스에서 사용하기 위해 출력합니다. 또한, 각 시뮬레이션 단계별 복셀 밀도 그리드를 출력하는데, 이는 헤어 충돌 및 헤어 섀도우 계산에 필요합니다.
다음 단계는 각 헤어 버텍스의 최종 위치를 결정하는 것입니다. 모든 헤어 스트랜드는 베이스 메시의 트라이앵글에 직접 스키닝됩니다. 애셋 임포트 단계에서 각 스트랜드 루트에 대해 부모 메시에 가장 가까운 트라이앵글, 바리센트릭 좌표, 탄젠트 프레임을 계산합니다. 각 스트랜드 루트별로 부모 트라이앵글 인덱스, 패킹된 바리센트릭, 트라이앵글 노멀 및 탄젠트 정보를 80바이트로 저장합니다. TBN(Tangent, Bitangent, Normal)은 옥탈(Octahedral) 인코딩을 사용합니다. 헤드 메시는 다양한 트라이앵글 인덱스를 가진 여러 LOD(Level of Detail)를 가지므로, 각 LOD에 대해 해당 정보를 별도로 베이킹해야 합니다.
런타임 시에는 모든 헤드 메쉬를 미리 스키닝하여, 스키닝 버퍼에서 변환된 트라이앵글을 가져와 헤어 스트랜드를 그에 따라 변환합니다. 스키닝이 완료된 후, 헤어 버텍스를 클립 스페이스로 변환하여 이후 계산을 위해 저장합니다. 상당한 VRAM을 요구하지만, 여러 패스에서 재사용 가능하므로 가치가 있습니다. 컴포지션 단계에서는 픽셀별 포지션이 필요하며, 이를 통해 모션 벡터 및 셰이딩을 위한 보간 계수를 계산합니다. 따라서 변환된 버텍스를 캐싱하는 것이 매우 중요합니다.

변환된 버텍스(vertices)를 사용하여 래스터라이즈(rasterize)할 세그먼트(segment) 목록을 생성합니다. 여기서는 보이지 않는 세그먼트를 걸러내는 거친 컬링(culling) 단계를 수행합니다. 컬링은 프로스트 컬링(Frostm culling), 오클루전 컬링(occlusion culling), 헤드 컬링(head culling) 세 가지 유형으로 진행됩니다.
오클루전 컬링 시에는 각 세그먼트를 축소된 깊이 버퍼(depth buffer)와 비교합니다. 클로즈업 장면에서 각 세그먼트가 화면을 많이 차지하는 경우, 전체 높이의 Z 체인(high Z chain)을 구축하는 것이 유리할 수 있습니다. 하지만 본 작업에서는 16배 축소된 깊이 버퍼만으로도 충분했습니다.
마지막 단계는 소위 페도라 컬링(fedora culling)입니다. 이는 인디아나 존스 영화의 상징적인 부분으로, 주인공이 모자를 쓰고 벗는 장면이 많아 모자를 뚫고 나오는 머리카락 문제를 해결해야 했습니다. 두 가지 형태를 사용하여 이를 해결했습니다. 첫 번째는 배제 상자(exclusion box)로, 모자 위의 모든 세그먼트를 컬링합니다. 그러나 모자 바로 아래 머리카락을 컬링하지 않아야 하는 작은 영역이 있습니다. 이를 위해 컬링 상자에서 잘라낸 구체(sphere)를 사용하여 해당 세그먼트를 보존합니다.
세그먼트가 컬링을 통과하면 가시성 비트(visibility bit)를 원자적으로(atomically) 높입니다. 원자 연산 횟수를 줄이기 위해 웨이브 내장 함수(wave intrinsics)를 활용하고, 실제 원자 쓰기(atomic write)는 웨이브당 한 번만 수행합니다. 이 단계에서 각 헤어 모델의 실제 화면 경계(real screen boundaries)를 계산하여 가시성 아틀라스(visibility atlas)에 필요한 공간을 확보합니다.
이제 래스터라이제이션(rasterization)으로 넘어가겠습니다. 하드웨어 래스터라이제이션은 렌더링하려는 프리미티브(primitive)가 작을 때 최적의 성능을 보입니다. 헤어 세그먼트는 픽셀보다 훨씬 얇은 경우가 많으므로 이는 유리합니다. 또한, 소프트웨어 래스터라이제이션을 선택한 다른 이유들도 있습니다. 가능한 한 많은 작업을 동기식 컴퓨트(sync compute)로 오프로드(offload)하고, 완벽한 안티앨리어싱(anti-aliased) 라인을 렌더링하기 용이하기 때문입니다.
이러한 이유들로 짧은 라인 세그먼트에 최적화된 자체 소프트웨어 보수적 래스터라이저(software conservative rasterizer)를 개발했습니다. 각 라인 세그먼트를 사다리꼴(trapezoid)로 간주하고 가시성 버퍼(visibility buffer)로 래스터라이즈합니다. 각 셰이더 레인(shader lane)은 하나의 세그먼트를 받아 간단한 2차원 루프를 사용하여 래스터라이즈합니다.
각 픽셀에서는 커버리지(coverage)를 계산하고, 전체 정밀도(full precision)의 깊이 버퍼에 대해 깊이 테스트(depth test)를 수행한 후, 원자 연산을 사용하여 가시성 버퍼에 출력합니다. 이 알고리즘은 매우 간단하지만 매우 느립니다. 종속 읽기(dependent reads)가 많고 캐시 활용도(cache utilization)가 이상적이지 않으며, 레인 발산(lane divergence)이 높습니다. 또한, 다중 가시성 버퍼에 쓰는 것 자체가 느린 연산입니다.
그렇다면 어떻게 하면 더 빠르게 만들 수 있을까요? 가장 비용이 많이 드는 작업인 가시성 버퍼 쓰기부터 살펴보겠습니다. 각 픽셀에는 깊이 순서대로 세 개의 프래그먼트(fragment) 레이어와 가산 픽셀 커버리지(additive pixel coverage) 레이어가 있습니다. 픽셀을 가시성 버퍼에 쓰기 위해 간단한 코드를 사용합니다. 이는 픽셀당 36개의 64비트 값과 가산 커버리지용 32비트를 사용하는 꽤 큰 가시성 버퍼를 필요로 합니다. 1080p 해상도에서 가시성 버퍼만으로 56MB가 소요되어 상당한 양입니다.
64비트 원자 연산은 성능상 괜찮지만, 후속 최적화와 메모리 사용량 감소를 위해 페이로드(payload)는 32비트를 사용하고자 합니다. 또 다른 문제는 이 코드에 종속적인 원자 연산이 많다는 점입니다. 이는 상당히 느립니다. 페이로드를 32비트에 맞추려면 타협이 필요합니다. 화면에 너무 많은 세그먼트가 렌더링되는 것을 원하지 않으므로, 모델당 최대 세그먼트 수를 22비트로 제한하는 것이 허용 가능했습니다. 그러면 나머지 10비트가 남습니다. 세그먼트 인덱스(segment index)로부터 모든 것을 재구성할 수 있지만, 원자 최소값(atomic minimum) 연산을 위해 깊이(depth)는 페이로드에 있어야 합니다.
하지만 10비트는 장면 깊이(scene depth)를 담기에는 턱없이 부족합니다. 대신 모델 경계 내에서 깊이 값을 다시 정규화하고 선형화(re-normalize and and linearized)합니다. 이렇게 하면 10비트로 충분합니다. 간혹 Z-fighting 아티팩트(z-fighting artifacts)가 발생하지만 눈에 잘 띄지 않습니다. 또 다른 중요한 결과는 페이로드에 헤어 모델 인덱스(hair model index)를 위한 공간이 전혀 남지 않는다는 것입니다. 따라서 단일 화면 가시성 버퍼 영역에 두 개의 모델이 프래그먼트를 출력할 수 없습니다.
따라서 단일 전체 화면 가시성 버퍼 대신 작은 타일(tile)의 아틀라스(atlas)를 사용합니다. 각 헤어 조각은 화면 공간 경계에 따라 아틀라스에서 타일을 할당받습니다. 겹치는 헤어 조각은 서로 다른 타일을 할당받으므로, 각 타일에는 하나의 헤어 모델만 포함됩니다. 또한, 헤어 아틀라스에 사용되는 메모리를 해상도와 분리할 수 있지만, 이는 자체적인 문제점도 동반합니다.
아틀라스는 유한한 크기를 가지며, 겹치는 헤어 모델은 아틀라스에 있는 것보다 더 많은 타일을 필요로 할 수 있습니다. 래스터라이제이션 전에 이를 감지하고, 모든 타일 특징이 아틀라스에 맞도록 각 타일을 다운스케일합니다. 이는 또한 부가적인 효과가 있습니다. 헤어 아틀라스의 픽셀 수가 고정되어 있으므로 래스터라이제이션에 대한 상한선이 항상 존재합니다. 다운스케일 시 가시적인 픽셀화를 피하기 위해 최종 합성 시 아틀라스를 확률적으로 샘플링합니다. 이를 위해 푸아송 디스크 분포(Poisson disk distribution)를 사용합니다.

이론적으로는 거의 무제한의 헤어(hair)를 표현할 수 있으나, 실제로는 절반 해상도(half res) 이상으로 작업할 필요는 없었습니다. 이처럼 다운스케일(downscale) 시의 시각적 결과물을 확인할 수 있습니다. 보통 카메라에 근접한 여러 캐릭터가 있고 디스플레이 해상도가 충분히 높을 때 이 기능이 활성화됩니다.
이전에도 언급했듯, 저희는 가시성 버퍼(visibility buffer)에 세 개의 최상위 레이어(top layers)를 사용합니다. 하지만 일반적으로 헤어 스트랜드(strand) 하나는 픽셀 면적의 약 20-25%만을 차지합니다. 세 개의 전면 샘플(front samples)로는 불투명(opaque) 커버리지를 얻기에 턱없이 부족했습니다.
순서 독립 투명도(order independent transparency)를 구현하는 것은 일반적으로 속도가 느리고 렌더링 과정을 상당히 복잡하게 만들기에 저희는 이를 원치 않았습니다. 단일 픽셀 내 수십 개의 프래그먼트(fragment)를 결합하는 빠른 근사치(approximation)가 필요했습니다.
저희에게 효과적이었던 방법은 해부학적 연산(anatomic operation)을 사용하여 커버리지를 누적(accumulate)하고, 컴포지션 단계(composition stage)에서 나중에 알파 블렌딩(alpha blended)된 커버리지를 재구성하는 것이었습니다.
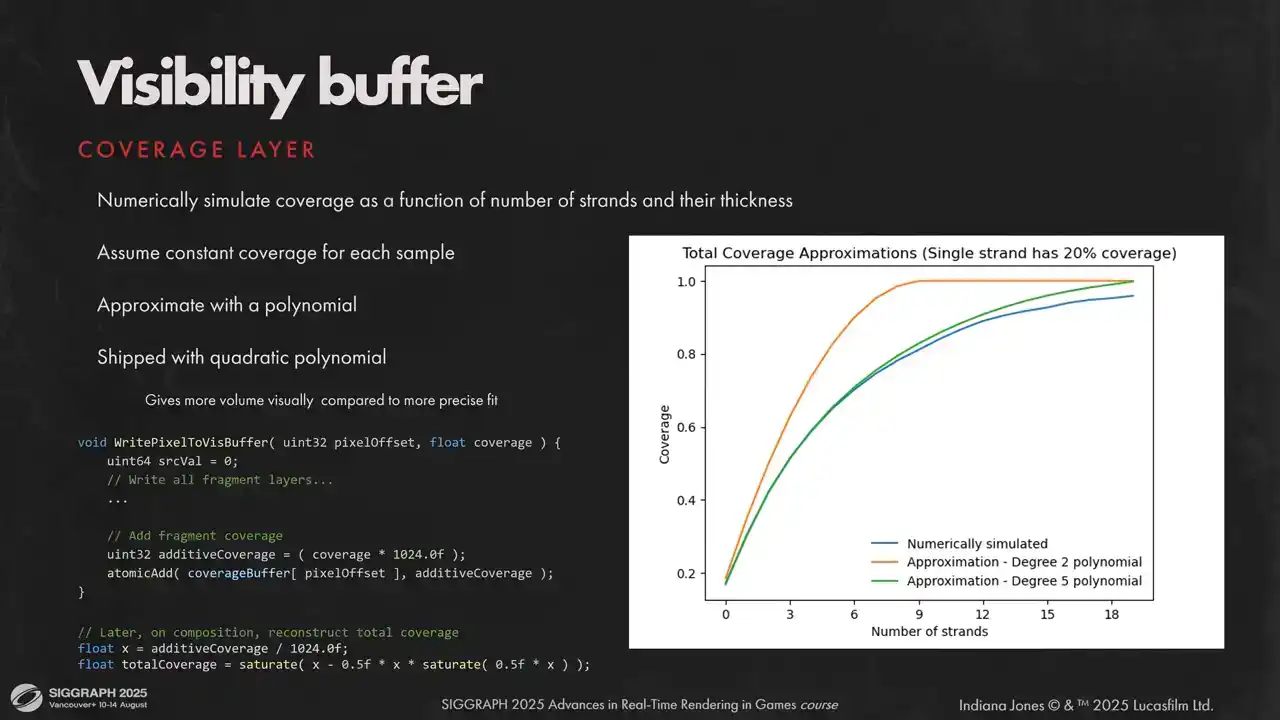
Additive coverage를 alpha blended로 변환하기 위해 몇 가지 가정을 하였습니다. 모든 strand가 유사한 screen space thickness를 가지며, 단일 pixel을 덮는 모든 strand가 유사한 BSDF properties를 갖는다고 가정합니다. 이를 바탕으로, 불투명한 선들을 여러 개 그려 각 선이 그려진 후의 정확한 total coverage를 offline으로 계산하여 additive coverage 함수로서 total coverage를 수치적으로 시뮬레이션할 수 있습니다. 이후, 이 수치 데이터를 polynomial로 근사하면 됩니다. 5차 polynomial이 매우 잘 맞는다는 것을 확인하였으나, 약간 더 저렴하고 시각적으로 더 불투명한 결과를 제공하는 2차 근사를 적용하였습니다.

여기 두 가지 근사치를 비교한 시각적 차이를 보실 수 있습니다. 보시는 바와 같이 결과물은 시각적으로 매우 유사하지만, 두 번째 근사치는
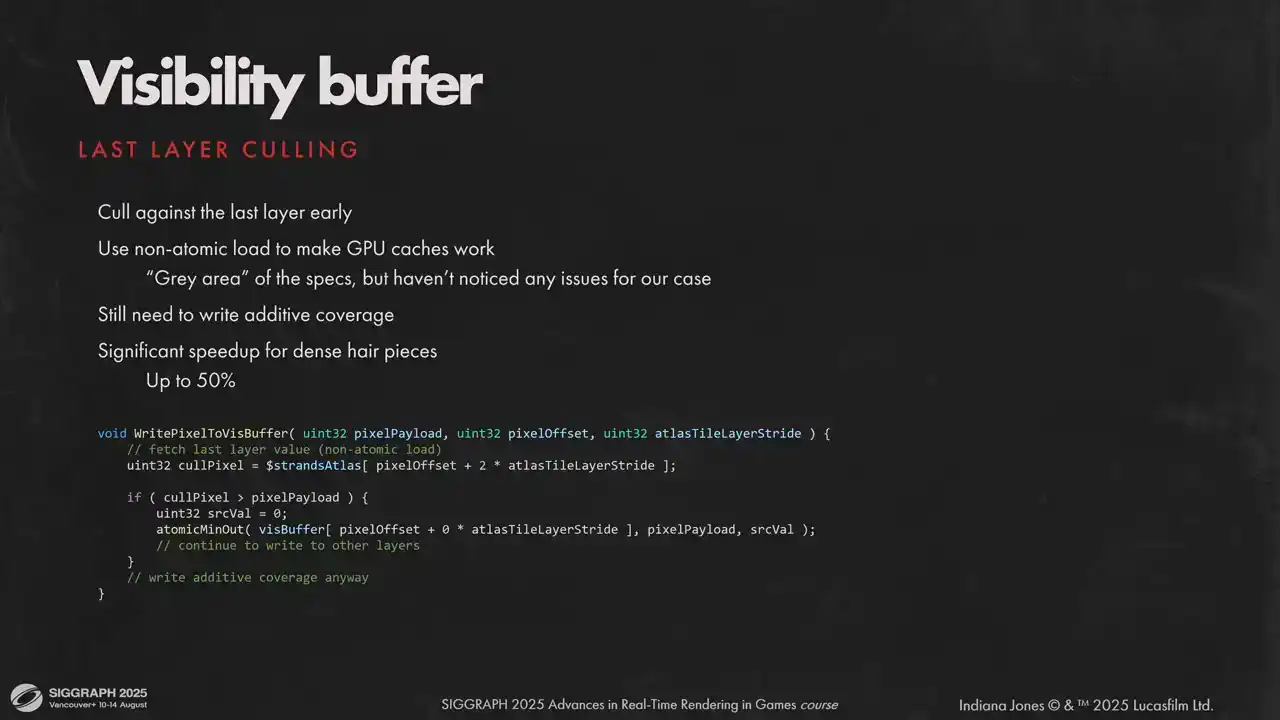
이것은 좀 더 불투명한 방식입니다. 다른 스케치한(sketchy) 방법이지만 매우 효율적인 최적화 기법으로, visibility buffer의 마지막 레이어에 대해 조기에 culled(제거)할 수 있습니다. 장점은 캐시를 활용하기 위해 non-atomic load를 사용할 수 있다는 것입니다. 단일 메모리 위치에 대한 atomic과 non-atomic 연산은 매우 애매한 영역이지만, 일부 모델에서는 래스터화 시간을 절반까지 줄여주며, 저희가 출시한 하드웨어에서는 아무런 문제가 발견되지 않았습니다.
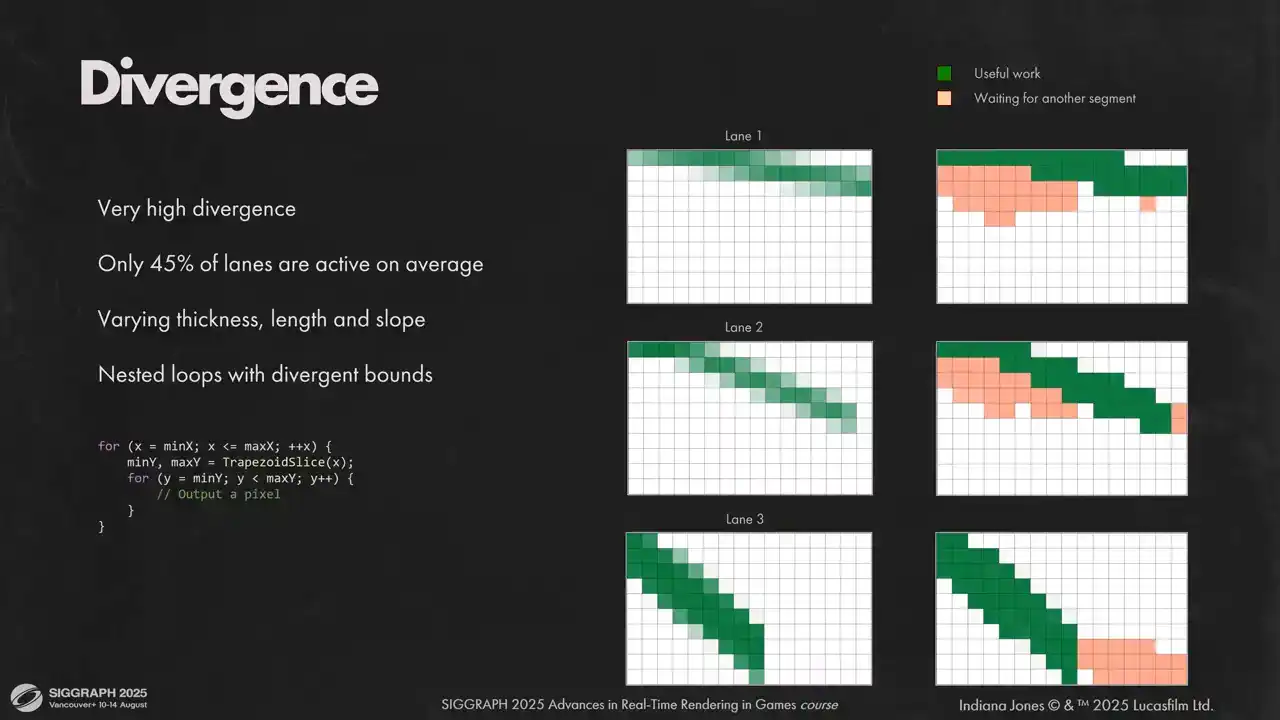
이제 다음 주제로 넘어가겠습니다. 저희가 해결해야 했던 또 다른 문제는 매우 높은 lane diversion이었습니다. 평균적으로, 주어진 시간 동안 저희 lane의 절반 미만이 유용한 작업을 수행하고 있었습니다. 저희는 divergent bounds를 가진 중첩된 두 개의 루프가 있었고, 매우 다른 segment들이 동일한 wave에 포함될 수 있었습니다. 어떤 것은 다른 것보다 더 두꺼울 수 있고, 다른 기울기를 가질 수 있습니다. wave 내의 모든 instruction은 lockstep으로 실행되기 때문에, 각 lane은 옆 lane이 다음 column으로 이동할 수 있었더라도 기다려야 했습니다. 이것은 슬라이드에서 볼 수 있습니다. 저희는 각 segment를 먼저 위에서 아래로, 그리고 왼쪽에서 오른쪽으로 rasterize합니다. 만약 현재 column에 활성 픽셀이 있는 segment가 있다면, wave 내의 모든 segment는 해당 segment를 기다립니다. 이것은 orange dummy 픽셀로 표시됩니다. 이러한 상황에서 저희가 할 수 있는 것은 두 루프를 하나로 flatten하고, 루프를 다음 column으로 이동하는 conditional statement로 변환하는 것입니다. 따라서 저희는 동시에 여러 lane에 대해 다른 column을 rasterize합니다. 이렇게 하면 다른 기울기와 두께에서 오는 diversion을 제거할 수 있습니다. segment에 대해 rasterize된 픽셀의 총 개수가 다른 경우에는 여전히 divergence가 발생할 것입니다.

다음은 언리얼 엔진 기반 렌더링 성능 최적화에 대한 원문의 핵심 내용을 한국어 게임업계에서 통용되는 자연스러운 표현을 사용하여 요약 및 번역한 결과입니다.
---
**파이프라인 최적화: Wave Divergence 해소 및 메모리 접근 효율 개선**
이전 단계에서 Wave Divergence의 한 원인을 제거했으므로, 다른 요인들을 살펴보겠습니다. 픽셀 수가 적은 Lane들은 래스터화 루프 마지막에 여전히 비활성화됩니다. 또한, 세밀한 Depth Test 역시 Divergence를 발생시키는 요인으로, Depth Test 통과 여부에 따라 Lane이 나뉘게 됩니다. 이러한 순차적인 연산들은 성능 저하를 유발하며, 숨기기 어렵습니다.
이 문제를 해결하기 위해, 비싼 Global Memory 연산들을 지연시킵니다. Pixel Write 요청을 위한 LDS(Local Data Share)를 할당하고, Wave 단위로 충분한 요청이 쌓이면 일괄 처리합니다. 더 이상 작업할 내용이 없는 Lane들은 래스터화 작업을 건너뛰지만, 다른 세그먼트의 Global Memory 연산을 수행합니다. 초기에는 Visibility Buffer 쓰기에만 적용했으나, 이후 Depth Test에도 동일한 메커니즘을 추가했습니다.
추가적인 Stack을 사용할 수 있으나, 각 Stack은 LDS 오버헤드를 증가시키므로 가장 비용이 많이 드는 Divergent 연산에만 사용하는 것이 좋습니다. Workgroup 내 각 Wave는 자체 Stack 공간을 사용하며, 메모리 영역은 겹치지 않습니다. Visibility Buffer 페이로드(32비트), 픽셀 위치, 정확한 Coverage를 저장해야 하므로, 작은 페이로드 크기는 LDS 사용량을 합리적으로 유지하고 Occupancy를 높이는 데 중요합니다.
Pixel Request Stack 작동 방식은 다음과 같습니다. 초기 두 번의 반복에서는 Stack에 충분한 픽셀이 없어 더 많은 요청을 추가합니다. 이 과정은 빠르므로 Divergence가 발생해도 문제가 되지 않습니다. Wave를 채울 만큼 데이터가 쌓이면, Stack의 최상단 요청을 가져와 Visibility Buffer에 씁니다. 이 연산은 비용이 많이 들지만, 모든 Lane이 함께 작업합니다. 이후 샘플 축적, Buffer로 플러시하는 과정을 반복합니다.
이러한 최적화를 통해, Wave Divergence를 낮추는 데 성공했습니다. 초기에 절반 이상 비활성화되었던 Lane들이 평균적으로 개선되었으며, Loop Flattening으로 10%의 Divergence 감소, Pixel Request Stack으로 추가 25%의 Divergence 감소를 이루었습니다. 결과적으로 셰이더 실행 속도가 약 두 배 빨라졌습니다.
**캐시 활용도 증대: Spatial Coherency 확보를 위한 Sorting**
작업이 고도로 병렬화되면서, 다음 문제로 낮은 캐시 활용도를 마주하게 됩니다. 이는 리소스 내에서 Strand가 무작위로 분포하기 때문이며, 각 Lane이 Visibility Atlas의 다른 부분에 접근하게 됩니다. 4000개의 연속적인 세그먼트가 여기저기 흩어져 있는 것을 볼 수 있습니다. 좋은 캐시 활용도를 위해서는 높은 세그먼트에 대한 Spatial Coherency가 필요합니다.
이에 대한 해결책으로 모델의 모든 세그먼트에 대해 Global Sorting을 적용했습니다. 완벽할 필요는 없으며, 같은 Workgroup 내 세그먼트들이 공간적으로 가깝도록 만드는 것이 중요합니다. 화면을 버킷으로 나누고, 버킷 크기는 Visibility Atlas 타일 크기와 유사하게 설정합니다. Culling 단계에서 버킷 카운터를 채우고 간단한 Counting Sort를 수행합니다. 이 과정은 100ms 미만으로 매우 빠릅니다.
Sorting 후 4000개 세그먼트가 정렬된 것을 볼 수 있습니다. Sorting의 Granularity가 완벽하지 않으므로, 래스터화 직전 각 Workgroup 내에서 추가 Sorting을 수행하는 것이 성능에 긍정적인 영향을 미칩니다. 이 최적화는 하드웨어에 따라 성능 향상 정도가 다르므로 측정해보는 것이 좋습니다.
래스터화 이후 Strand Space Shading 단계에서는 각 세그먼트에 대한 많은 데이터를 가져오게 됩니다. 래스터화와 동일한 Sorting 순서를 사용하면 L2 캐시 히트율이 낮아지므로, 세그먼트를 원래 순서대로 다시 정렬해야 합니다. 이 경우 버킷을 사용할 필요 없이 GPU가 Wave를 실행하는 순서를 활용할 수 있습니다. 혹은, 공간적으로 정렬된 Visible Segment 목록과 정렬되지 않은 Visible Vertex 목록을 별도로 저장하는 방법도 있습니다. 이는 메모리를 더 많이 사용하게 됩니다.
**Shading 최적화: Per-Vertex Shading 및 Self-Shadowing**
래스터화 파트가 마무리되었으므로 Shading 단계로 넘어갑니다. 부드러운 Shading과 성능 향상을 위해 Per-Vertex Shading을 사용합니다. Marshmorm의 Shading 모델을 기반으로 하며, Brian Karras의 발표에서 소개된 Reflection Lobe 근사치와 Sebastian Tafuri의 발표에서 제시된 다른 Lobe들을 사용합니다. 모델은 Untinted Reflection, Backlit 시 보이는 Transmitted Lobe, 그리고 두 번째 Tinted Reflection Lobe로 구성됩니다.
아티스트 편의와 마지막 조정을 위해 각 Lobe에 PBR이 아닌 스칼라 값을 추가했습니다. Shading 모델 자체에 대한 자세한 설명은 생략하고, Self-Shadowing에 집중하겠습니다. Marshmorm 모델은 매우...

인간 머리카락에 대해 만족스러운 현실적인 결과를 얻었으나, 대부분의 광원 방향에서 반사 및 투과 경로가 매우 밝게 나타나는 문제가 있었습니다. 따라서 머리카락이 보기 좋게 보이려면 모든 광원에 대해 충분한 Self-shadowing이 필수적입니다. 이는 두 가지 이유로 까다로운 상황을 만듭니다. 첫째, 게임에서는 성능을 위해 그림자를 생성하지 않는 Unshadowed Light를 사용할 수 있습니다. 둘째, 그림자를 생성하는 Light만을 사용하더라도 머리카락에 영향을 미치는 Light 수를 최소화해야 합니다. Cinematic용 설정은 매우 복잡할 수 있습니다. 간단한 방법 중 하나는 Unshadowed Light에 대해 Transmission Path를 비활성화하는 것이지만, 결과는 여전히 만족스럽지 못했습니다.

이상적인 상태에서 Reflection path는 여전히 많은 에너지를 가지고 있습니다. Self-shadowing을 위해 여러 접근 방식을 고려했습니다. 처음에는 Deep opacity maps를 고려했지만, 메모리 요구 사항 때문에 결국 폐기되었습니다. 각 머리카락 조각을 각 조명에 대해 래스터화해야 한다는 점도 저희에게는 시작조차 할 수 없는 문제였습니다. 메인 뷰로 머리카락을 래스터화하는 것만으로도 예산의 상당 부분을 차지합니다.
두 번째로 고려한 옵션은 시뮬레이션 패스에서 얻은 머리카락 밀도 볼륨에서 Raymarching을 통해 런타임 시 Global scattering을 추정하는 것이었습니다. 이는 메모리 사용량이 적고 추가적인 래스터화 패스가 필요하지 않습니다. 밀도 볼륨 해상도와 Ray marching 스텝 수를 조정하여 추적 속도를 제어할 수 있지만, 확장성 문제가 있습니다. 각 머리카락 셰이딩 포인트는 각 조명을 향해 볼륨을 Raymarch해야 합니다. 하지만 이 방식에서 얻는 시각적 결과는 대부분의 그룸에서 전반적으로 좋습니다.
그러나 이 접근 방식으로는 고주파수 섀도잉을 얻기 어렵습니다. 또한 일부 머리카락 조각은 상당한 해상도가 필요합니다. 예를 들어, 이 머리카락 조각은 보이는 Self-occlusion artifacts가 있음을 알 수 있습니다. 저희 콘텐츠의 경우, 일부 그룸은 artifacts(과도한 차폐 또는 누출) 없이 섀도잉을 해결하기 위해 각 축에 256개의 복셀이 필요했습니다.
또 다른 시도한 옵션은 이전 접근 방식의 수정이었습니다. 조명을 향해 Raymarching하는 대신, 고정된 수의 Ray trace를 확률적으로 수행하여 각 셰이딩 포인트에 대한 Spherical visibility function을 얻고 이를 Spherical harmonic 또는 Spherical gaussian으로 인코딩합니다. 이전 옵션과 비교할 때, 이 가시성 프로브 수를 셰이딩 포인트와 독립적으로 조정할 수 있습니다. 네 개의 정점당 하나의 프로브를 시도했으며, 하나의 정점당 하나의 프로브와 결과가 매우 유사했습니다.
더욱이, 조명 수에 더 이상 제한받지 않습니다. 셰이딩 포인트에 영향을 미치는 조명 수와 상관없이 가시성을 해결하기 위해 하나의 룩업만 수행합니다. 단점은 시간이 많이 소요되고, 머리카락이 너무 부드러워지는 것을 방지하기 위해 이전 접근 방식과 유사하게 그리드 해상도가 매우 높아야 한다는 것입니다. 예를 들어, 여기 보이는 가시성 패스는 단일 머리카락 조각에 6ms가 소요됩니다.
이것을 훨씬 더 최적화하고 여러 프레임에 걸쳐 작업량을 분산시킬 수도 있었지만, 시각적 품질이 저하될 것이며 이미 이미 충분하지 않습니다.
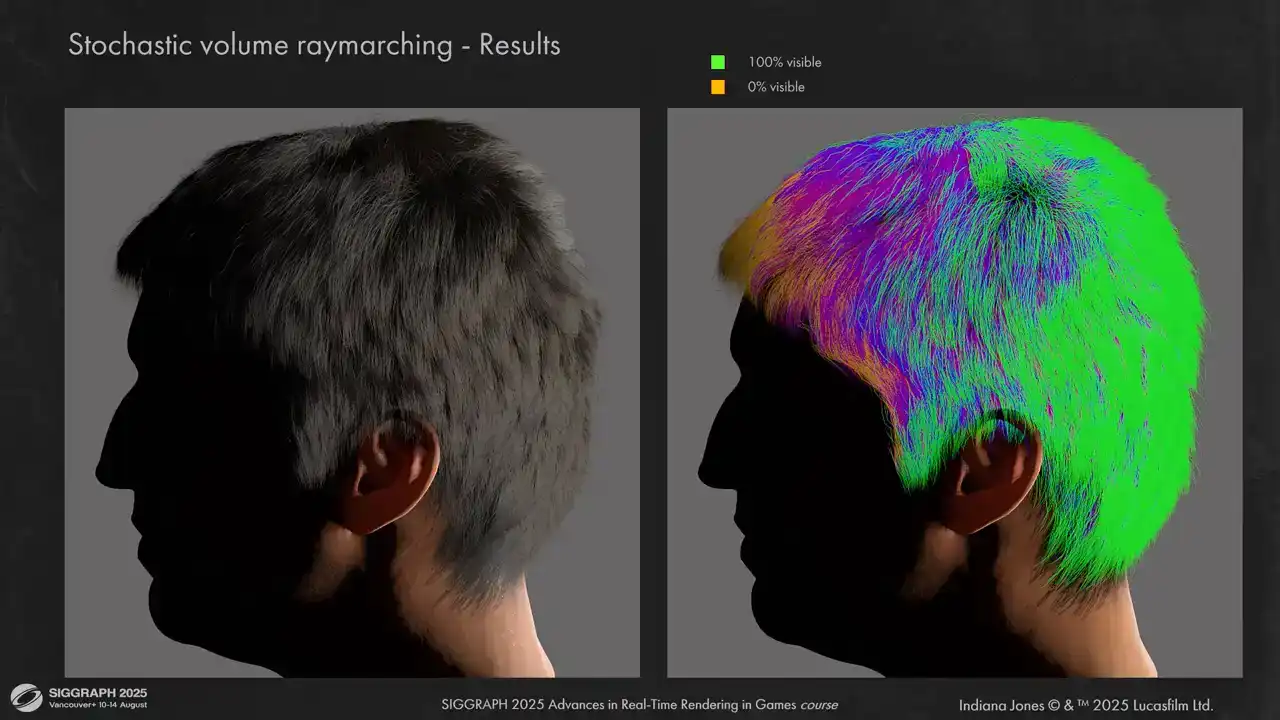
단순한 groom에서의 결과는 이렇습니다. 오른쪽을 보시면 단일 광원에 대한 visibility representation을 확인하실 수 있습니다. Lighting은 그럴듯하지만 다소 평면적인 느낌입니다.

하지만 이 과정을 통해 몇 가지 중요한 사실을 알게 되었습니다. 첫째, 대부분의 groom은 상당히 정적이고 짧다는 점입니다. 슬라이드에 보이는 가장 긴 헤어스타일이 그 예시입니다. 둘째, self-shadowing의 핵심은 각 segment의 짧은 주변부이며, 애니메이션이나 바람에도 크게 변하지 않는다는 것입니다.
이러한 제약 조건들을 활용하여 visibility를 한 번만 bake하고 여러 프레임에 재사용할 수 있었습니다. 실제로 저희가 구현한 방식은 ray marching 대신 software ray tracing을 사용하여 offline으로 bake하는 것이었습니다. Ray tracer를 사용함으로써 라이트 개수에 관계없이 각 hair strand에 대한 high-frequency self-shadowing을 거의 무료로 얻을 수 있었습니다. 또한 parent mesh에 대해서도 trace를 수행하여, 머리카락은 항상 머리에 의해 그림자가 드리워지도록 하였습니다.

Baked visibility를 모션 환경에서 사용할 때 깨질까 우려했습니다만, 결과는 기대 이상으로 잘 유지되었습니다. 예를 들어, 강풍 상황에서는 약간의 artifact가 보일 수 있으나, 이는 허용 가능한 수준이었습니다.

저희의 경우, baked ray traced visibility 결과는 다음과 같습니다. 보시는 바와 같이 high frequency details를 매우 훌륭하게 처리함을 알 수 있습니다.
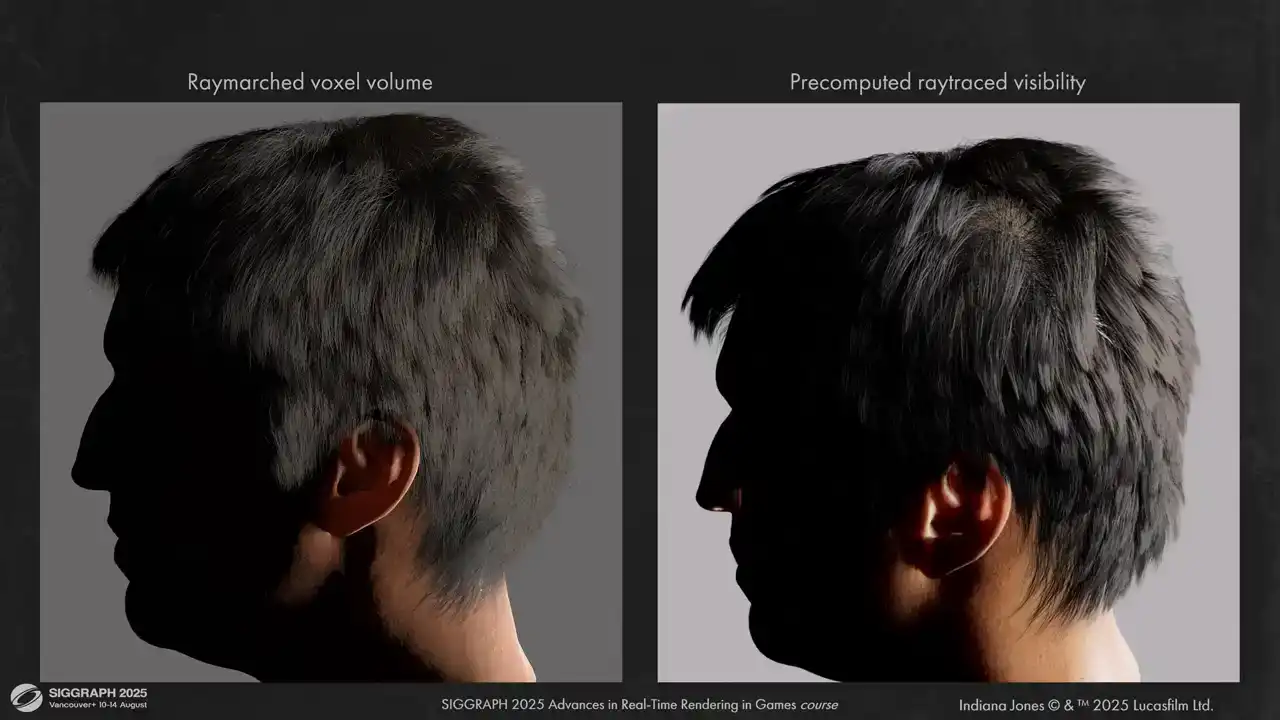
볼륨 레이 마칭(volume ray marching)과 사전 계산된 레이 트레이싱(pre-computed ray tracing) 간의 몇 가지 비교 결과를 보여드립니다. 결과물의 입체감이 훨씬 뛰어납니다.
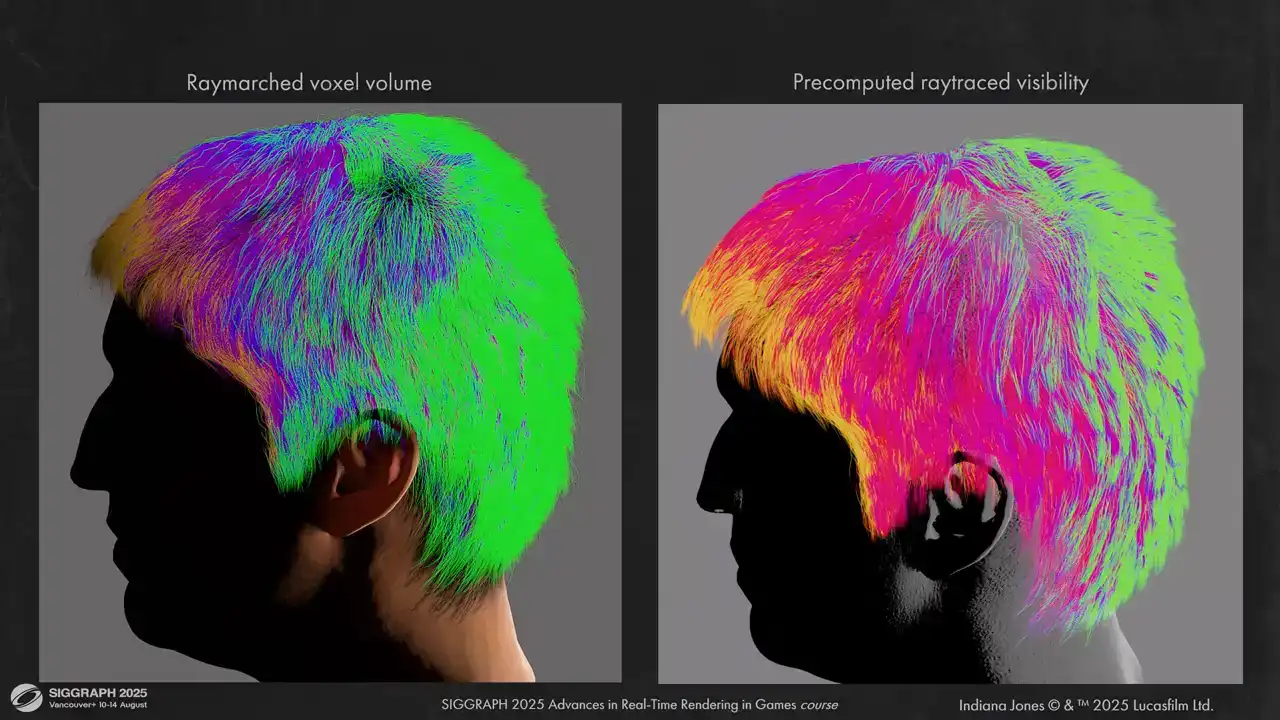
귀 주변의 shadowing이 훨씬 정확해진 것을 보실 수 있습니다. 왼쪽에서 발생했던 것처럼 leak이 보이지 않습니다.
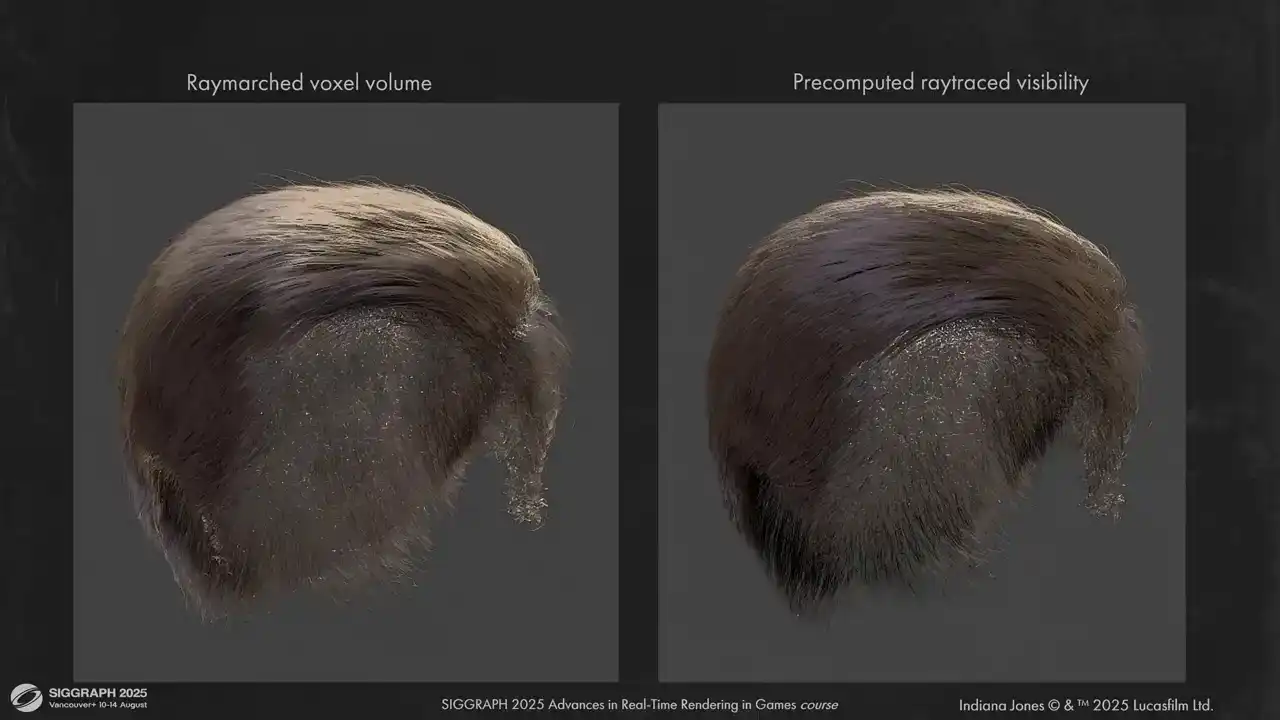
그리고 다른 헤어 피스들도 있습니다. 예를 들어 여기 인디아나 존스가 있습니다. 복셀 그리드를 사용하지 않을 때 self-occlusion이 문제가 되지 않음을 보실 수 있습니다.
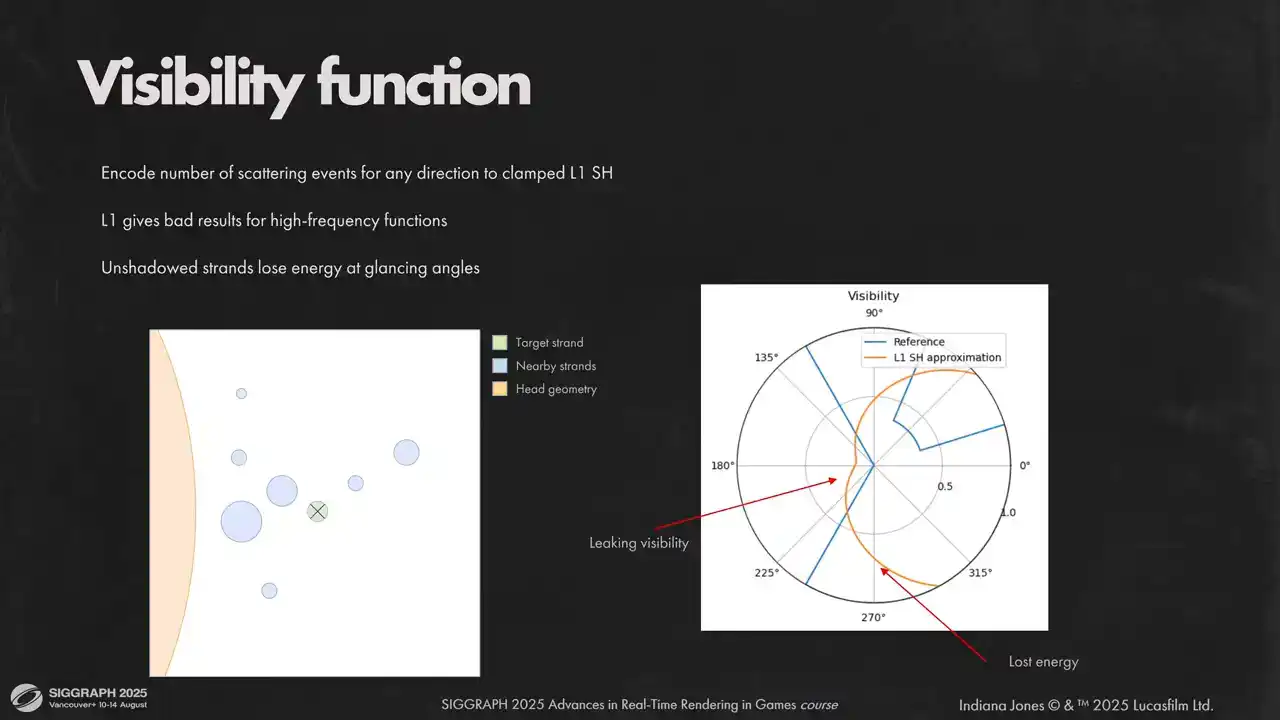
가시성 함수(visibility function)에는 적분 단순성, 낮은 메모리 요구 사항, Ringing Artifact 부재를 이유로 Clamped Low-order Spherical Harmonic을 사용합니다. Low-order Spherical Harmonic은 고주파수 데이터를 잘 포착하지 못하므로, 가시성을 직접 인코딩하는 대신 특정 방향의 평균 산란 횟수(average number of scattering events)를 인코딩합니다. Spherical Harmonic을 직접 사용할 경우, 오른쪽 극좌표 플롯(polar plot)에서 고주파 각도 디테일(angular details)을 잃는 것을 명확히 볼 수 있습니다. 이는 빛 누수(light leaking)와 에너지 손실(energy loss)을 유발합니다.

빛이 닿지 않은 레이(ray)에 편향(bias)을 적용하여 이 문제를 해결합니다. 이는 비스듬한 각도에서 발생하는 음영(overshadowing)을 피하고 명암(light and shadow) 간의 더 날카로운 전환을 얻는 데 도움이 됩니다. 그렇지 않으면 후광(backlit) 효과가 적용된 헤어의 빛나는 정도가 크게 감소하게 됩니다.

실제 콘텐츠에 적용된 모습을 보실 수 있습니다. Biases는 훨씬 더 정확한 이미지를 제공하며, Counter-backlit lighting 효과도 유지됩니다.

향후 작업에서는 다른 spherical functions와 dynamic recalculation for visibility를 실험해 보는 것이 흥미로울 것입니다. 이를 통해 강풍과 아주 긴 머리카락을 더 잘 처리할 수 있습니다.
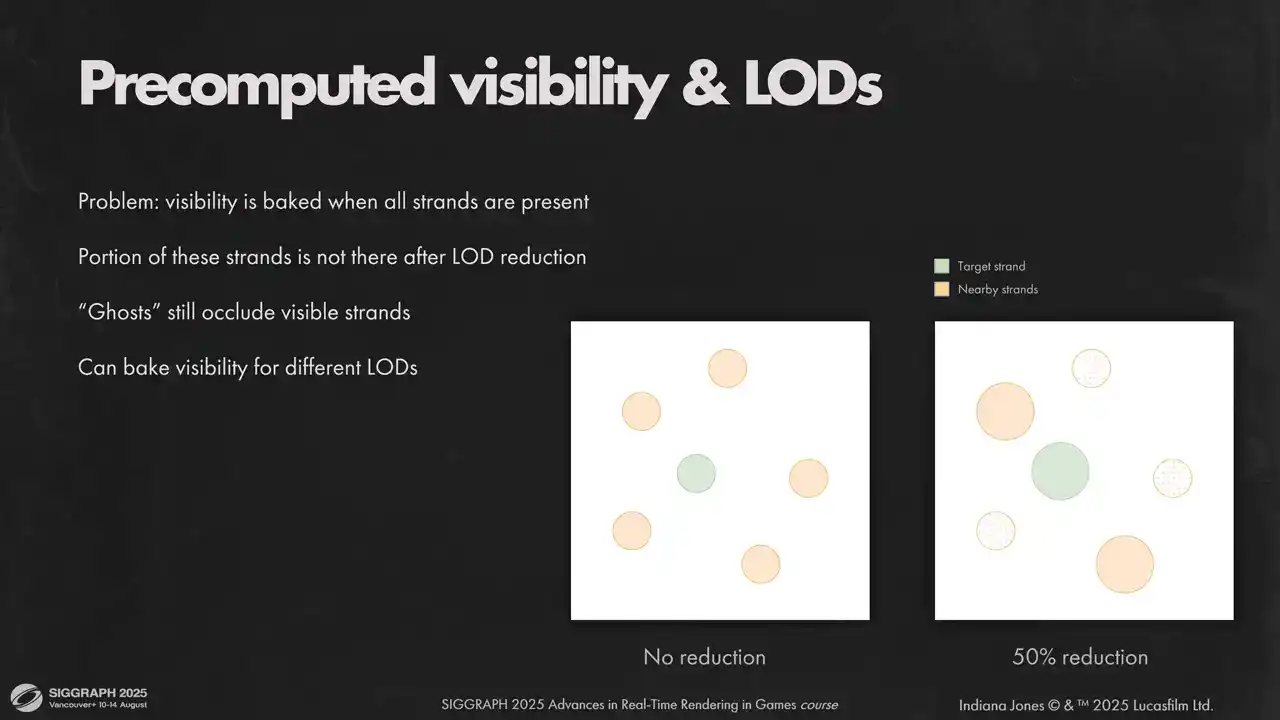
사전 계산된 가시성(pre-computed visibility)은 로드 시스템(load system)과의 상호작용에서 또 다른 문제를 야기합니다. 저희는 원본 모델의 일부 스트랜드를 직접 로드하는 방식으로 처리합니다. 이는 사전 계산된 가시성에도 동일하게 적용됩니다.
하지만 이 데이터는 축소되지 않은(unreduced) 모델을 기준으로 계산되었으며, 로드 시스템에 의해 제거된 스트랜드와의 충돌 정보를 포함하고 있습니다. 이상적으로는 가능한 모든 로드에 대해 가시성을 다시 베이킹(rebake)해야 하지만, 스트랜드 수만큼 로드가 존재하기 때문에 메모리 사용량이 과도하게 늘어납니다.
이러한 이유로, 전통적인 고정 단계 LOD(fixed-step LODs)를 사용하는 것이 더 나은 선택이었을 수 있습니다.
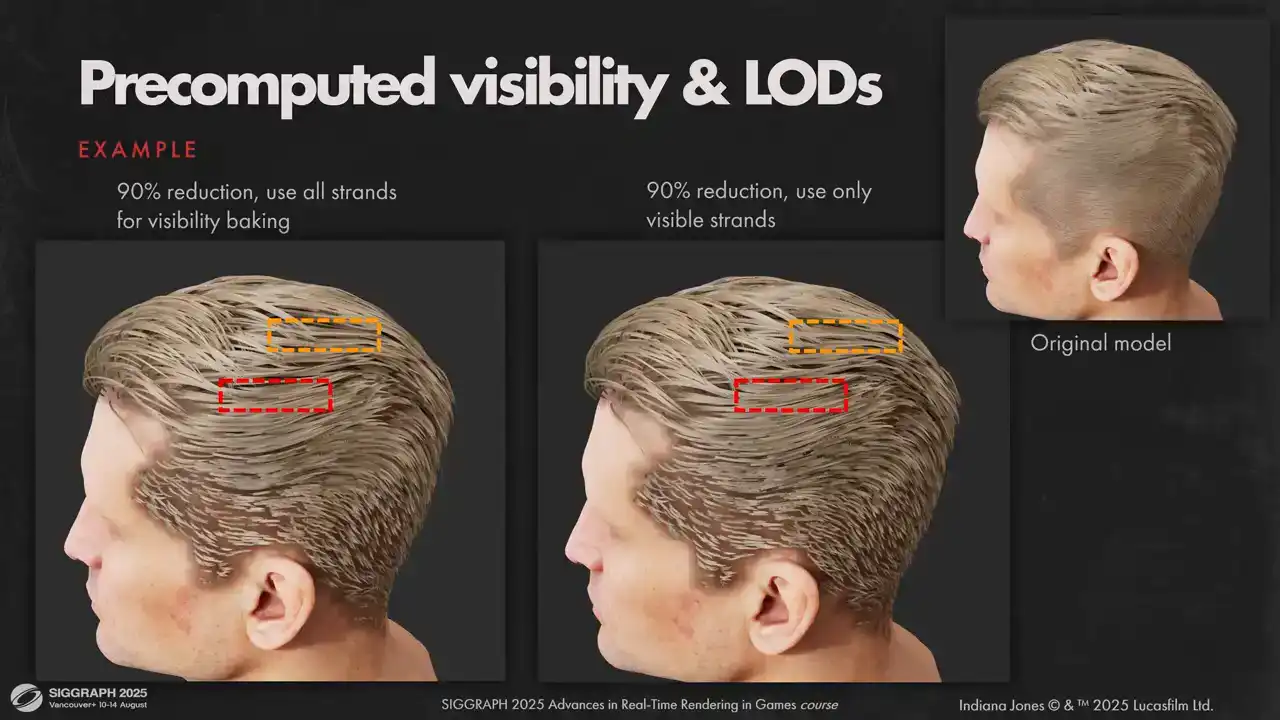
실제 구현에서는 해당 artifact가 크게 눈에 띄지 않아 원본 lot system을 유지했습니다. 자세히 살펴보면 아주 미미한 차이를 확인할 수 있으나, 심각한 수준은 아닙니다.

이제 셀프 쉐도잉 처리가 완료되었으므로, 헤어가 다른 오브젝트에 드리우는 그림자를 계산해야 합니다. 스킨 픽셀의 경우, 헤어 셀프 쉐도잉에 사용했던 방법과 유사하게 volumetric raymarching shadows를 사용합니다. 이 방법은 ambient occlusion과 specular occlusion까지 얻을 수 있다는 추가적인 장점이 있습니다. 큰 픽셀에 대해서만 이 연산을 수행하므로 충분히 빠릅니다. 그림자가 자연스럽게 확산되는 헤어에 아주 잘 작동했습니다. 스트랜드를 섀도우 맵으로 래스터화할 필요가 없어 엔지니어링 노력이 절감되었습니다. 성능 확장성 또한 만족스럽습니다.
하지만 이 방법이 완벽하지는 않습니다. 밀도 볼륨이 시뮬레이션에서 생성되기 때문에, 한 개의 헤드 조인트에만 적용 가능하며, 유연성이 매우 높은 동물의 털에는 사용할 수 없습니다. 또한, 헤어가 다른 오브젝트에 드리우는 그림자는 여전히 필요하며, 헤어 볼륨 교차를 위한 가속 구조를 만들고 싶지는 않았습니다. 일반적으로 헤어 그림자 누락은 크게 눈에 띄지 않지만, 플레이어 캐릭터의 경우 그렇지 않습니다. 여기 바닥에서 누락된 그림자가 매우 눈에 띄는 것을 볼 수 있으며, 메인 캐릭터의 실루엣을 해치고 싶지 않습니다. 이 경우, 면이 뒤집힌 매우 간단한 sculpted shadow proxy를 사용했습니다.

shadow maps로 렌더링하는 것은 매우 빠르고 아티스트가 제작하기에도 매우 간편합니다. 각 헤어 버텍스의 가시성(visibility) 및 셰이딩(shading) 정보가 준비되면, 이를 최종 이미지로 합성해야 합니다. 각 헤어 모델은 visibility atlas 내에서 고유한 공간을 가지므로, 각 모델을 개별적으로 합성해야 합니다. 이를 위해 각 모델에 대해 카메라를 향하는 쿼드(quad)를 그립니다. 이 과정은 다른 알파 블렌딩(blended) 지오메트리(geometry)와 함께 뒤에서 앞으로(back-to-front order) 렌더링됩니다. 이러한 방식은 복잡한 투명도(transparency) 설정이 포함된 장면을 처리할 수 있게 합니다.

하나의 방식으로 통합합니다. 때로는 이것이 버그의 원인이 될 수 있습니다. sorting이 올바르지 않을 경우, 몇 가지 heuristic을 사용하여 이를 해결합니다. 메인 hairpiece 이전에 항상 facial hair을 먼저 draw하려고 합니다. 모든 hair는 sorting 시 0.5미터만큼 bias를 적용합니다. 따라서 soft blending을 사용하는 smoke particle은 가까이 있을 때 항상 hair 이후에 draw됩니다. hair는 렌더링 시 depth에 기록하므로 particle soft blending이 제대로 작동합니다. 이는 sorting이 잘못된 몇몇 부분을 숨기는 데 도움이 되지만, sorting이 정확하지 않을 때 여전히 눈에 덜 띄는 artifact가 존재합니다.

대부분의 셋업은 별도의 수동 튜닝 없이 바로 작동했습니다. 그러나 일부 복잡한 셋업은 sorting biases 조정이 필요했습니다. 예를 들어, 이 샷을 보시면 저희에게 다소 문제가 되었던 셋업이 있습니다. 많은 투명 오브젝트가 겹치고 머리카락을 정확하게 정렬하는 것이 까다로운 경우입니다.
저희는 먼저 비행기 뒤에 연기를 렌더링합니다. 그 다음 캐릭터 뒤에 유리, Gina의 머리카락, Indie의 속눈썹과 눈썹, 주요 머리카락 뭉치 순으로 렌더링했습니다. 마지막으로 캐릭터 앞의 전면 유리를 렌더링했습니다.
이 모든 것을 올바른 순서로 렌더링하기 위해 유리 부분의 sorting biases를 조정하고 front faces와 back faces를 별도로 렌더링해야 했습니다.

이제 단일 헤어피스를 사용하여 컴포지션하는 방법을 살펴보겠습니다. 이전 섹션에서 기억하시겠지만, 각 헤어 픽셀당 세 개의 앞쪽 세그먼트와 총 커버리지(total coverage)만 저장합니다. 그리고 모든 헤어 조각(hair fragments)에 대한 결합된 라이팅(combined lighting)을 재구성해야 합니다. 첫 세 샘플의 커버리지는 일반적인 알파 블렌딩(alpha blended) 커버리지로 모델링했습니다. 또한 Visibility Atlas에서 총 커버리지 값을 얻습니다. 누락된 부분의 라디안(radians)은 기존 샘플의 가중 합(weighted sum)으로 모델링합니다. 재구성하려는 샘플과 더 가까운 세 개의 샘플 중에서 카메라에서 더 멀리 떨어진 샘플을 선호합니다. 이는 일반적으로 세 개의 앞쪽 샘플로 충분한 근접 거리와 더 많은 라이팅 정보가 재구성되는 원거리에서 좋은 외형을 제공합니다.
마지막으로 모션 벡터(motion vectors)입니다. 완벽한 모션 벡터를 갖는 것은 업스케일러(upscalers), TAA 및 모션 블러(motion blur)가 작동하는 데 매우 중요합니다. 이를 위해 글로벌 포스트 트랜스폼 버텍스 캐시(global post-transform vertex cache)를 활용합니다. 캐시를 압축하고 다음 프레임에서 완벽한 모션 벡터를 계산하는 데 사용합니다. 콘솔 및 패스 트레이싱(pass traced)되지 않은 PC 버전은 포스트 트랜스폼 헤어 버텍스 위치의 처음 두 컴포넌트를 각 두 바이트로 압축하여 사용합니다. 이는 보수적 래스터(conservative raster)에서 좋은 결과를 제공합니다. 그러나 보수적이지 않으며 TAA를 사용하여 헤어를 재구성하고 추가 몇 메가바이트를 감당할 수 있다면 전체 정밀도(full precision) 사용을 권장합니다. 이는 이미지 선명도를 상당히 향상시킵니다.

현재 저사양(low spec) 구현에 필요한 메모리 사용량을 보실 수 있습니다. 고사양(high spec)의 경우, 62MB에서 두 배 늘어난 90MB의 렌더링 데이터가 필요합니다. 에셋(asset)에 대한 헤어 스트리밍(hair streaming) 구현 시간이 부족하여, 리소스 의존적인 메모리 부하는 씬(scene)에 따라 달라집니다.
향후 작업으로는 시뮬레이션 요구사항을 줄이고 에셋 스트리밍을 구현하고자 합니다. StrandHair 개발 경험을 통해 배운 점을 요약하자면, StrandHair는 현재 세대 하드웨어에서 헤어 표현을 위한 주요 솔루션으로 충분히 빠르다는 것입니다. 다만, 타겟을 명확히 설정하고 상황에 맞춰 리소스를 선택해야 합니다. 또한, 시스템 모든 부분에 대한 명확한 최악 시나리오(worst-case scenario) 정의는 콘텐츠의 한계를 극복하는 데 매우 중요합니다.
소프트웨어 래스터라이저(software rasterizer) 선택은 문자열(strings) 렌더링에 있어서 올바른 결정이었습니다. 빠른 성능 구현에 상당한 시간이 소요되지만, 그 결과는 충분히 가치가 있었습니다. 마지막으로, 동적 헤어(dynamic hair) 최적화 작업이 더 필요합니다. 현재는 성능과 움직임의 디테일 사이에서 선택해야 하는 상황입니다.