[KOR][100]Rerank-for-better-RAG-(Explained)
https://www.youtube.com/watch?v=K1F8BIgcoNk
## 검색 증강 생성(RAG) 문제 해결을 위한 재순위화(Re-ranking) 기법
검색 증강 생성(Retrieval Augmented Generation, RAG) 문제를 검색 문제로 접근하고, **재순위화(Re-ranking)**를 활용하여 검색 결과의 정확도를 높이는 방법에 대해 설명합니다.
---
### 1. 재순위화의 필요성
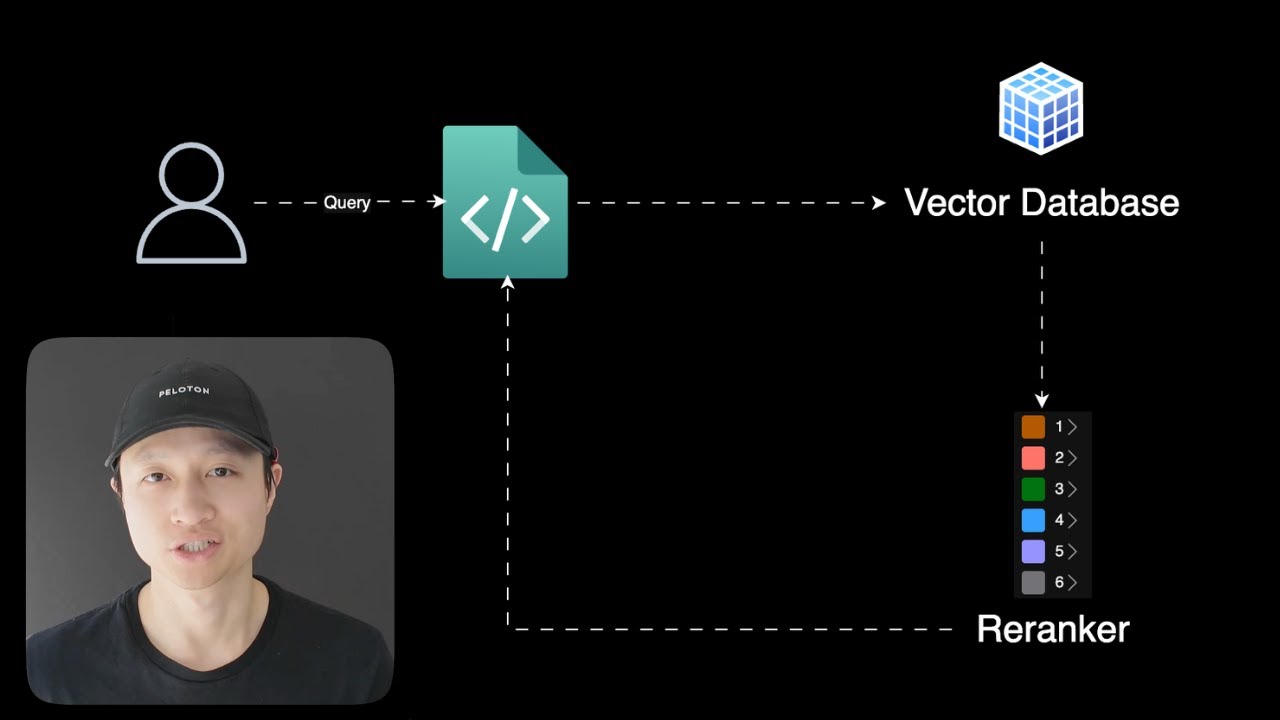
* **RAG 시스템의 기본 흐름:**
* 사용자 쿼리 -> 애플리케이션 -> 벡터 데이터베이스 (Pinecone, VV8, PGVector 등)
* **대규모 언어 모델(LLM)의 한계:**
* 제한된 컨텍스트 길이
* 높은 리콜(recall)을 위한 **과다 검색(over-retrieving)** 필요성 증가
* 수많은 관련 문서 중 최대한 많이 검색하고자 할 때 발생
* **문제점:** 과다 검색 시, LLM이 관련 없는 정보까지 처리하여 부정확한 답변 생성 가능성 존재
* **해결 방안:** LLM이 더 정확한 답변을 생성하도록 돕는 재순위화 기법 도입
---
### 2. 재순위화란?
* **정의:** 검색된 문서들의 관련성 점수를 재평가하여 가장 관련성 높은 문서를 상위에 배치하는 기술
* **작동 방식 (현대적 재순위화):**
* LLM을 사용하여 문서의 맥락을 이해하고 관련성 순서대로 재정렬
* **예시:** Sabrina Carpenter의 노래 검색 시, 커피 관련 노래(Espresso)가 검색 결과 하단에 있더라도 재순위화를 통해 상위로 끌어올려 LLM이 쉽게 인식하도록 함
---
### 3. 재순위화 구현 방법
#### 가. 수동 재순위화 (Manual Re-ranking)
* **개요:** 별도의 재순위화 서비스(예: Cohere)를 활용하여 검색된 문서들을 재순위화하는 방식
* **구현 단계:**
1. **문서 검색:** 쿼리를 벡터 데이터베이스에 전송하여 문서 검색 (과다 검색)
2. **데이터 변환:** 재순위화 서비스에 맞는 형식으로 데이터 변환 (문서 텍스트, 문서 ID 분리)
* 문서 ID는 재순위화 후 문서 위치를 파악하는 데 사용
3. **재순위화:**
* Cohere의 `.rerank` 함수 사용
* 사용자 쿼리, 문서 텍스트, 문서 ID를 입력하여 관련성 높은 상위 N개 문서 반환
* 검색 시 과다 검색된 문서 중 N개를 선택하여 재순위화 (리콜 향상 목적)
4. **LLM 입력 준비:** 재순위화된 문서들의 내용을 하나의 큰 문자열로 결합
5. **LLM 답변 생성:** 결합된 텍스트를 LLM에 입력하여 최종 답변 생성
* **장점:** 검색 결과의 정확도를 높일 수 있음
* **단점:**
* 데이터 변환 등 추가적인 복잡한 코드가 필요
* 별도의 재순위화 서비스 설정 및 관리 필요
* 다양한 재순위화 모델 관리의 어려움
#### 나. 내장 재순위화 (Built-in Re-ranking)
* **개요:** 검색 및 재순위화 기능을 통합 제공하는 서비스(예: Vectorize)를 활용하는 방식
* **구현 단계:**
1. **서비스 설정:** Vectorize와 같은 서비스에서 웹사이트 크롤링 등 데이터 소스 설정
2. **검색 및 재순위화:**
* 애플리케이션에서 Vectorize의 검색 엔드포인트 호출 시 `re-rank=True` 옵션 설정
* 별도의 데이터 변환이나 재순위화 서비스 호출 없이, 검색과 동시에 재순위화된 결과 반환
* **장점:**
* **복잡성 대폭 감소:** 3단계로 간소화 (수동 방식 5단계)
* 별도의 재순위화 서비스 설정 및 관리 불필요
* 최신 기술 및 모범 사례가 통합된 서비스 활용 가능
* 개발자는 검색 및 재순위화의 복잡성에 신경 쓸 필요 없이 애플리케이션 개발에 집중 가능
* 리콜과 정밀도(precision) 모두 향상
---
### 4. 결론
* 재순위화는 RAG 시스템의 정확도를 높이는 중요한 기법입니다.
* **내장 재순위화** 기능을 제공하는 서비스를 활용하면 복잡성을 줄이면서도 높은 성능을 달성할 수 있습니다.
* 재순위화를 통해 검색 결과의 **정밀도**를 높이면 LLM이 더 나은 답변을 생성하도록 도울 수 있습니다.