https://youtu.be/-zLGgaEsBb0?si=FUesxhnwLk7KwMj7
# RDBMS vs. 벡터 DB: 핵심 기능, 활용 방안 및 차이점
## 1. 데이터베이스의 기본 이해
* **데이터베이스 (Database):** 데이터를 효율적으로 저장, 관리, 검색하기 위한 체계적인 시스템
* **다양한 종류:** 목적과 유형에 따라 존재하며, 본 영상에서는 RDBMS와 벡터 DB를 중점적으로 다룸
## 2. 관계형 데이터베이스 (RDBMS)
* **정의:** Relational Database Management System의 약자로, 데이터를 정형화된 테이블 형태로 저장
* 테이블은 행과 열로 구성되며, 테이블 간의 관계를 정의하여 데이터를 연결
* **주요 특징:**
* **데이터 무결성 및 일관성 유지:** 트랜잭션 오류 발생 시 계산 오류나 문제 방지
* **정형 데이터 처리:** 표 형태의 데이터 (엑셀과 유사) 처리
* **엄격한 스키마:** 데이터 타입을 미리 정의하고 데이터 삽입 (숫자, 문자열, 날짜 등)
* **주요 기능:**
* **CRUD (Create, Read, Update, Delete):** 데이터 생성, 조회, 수정, 삭제
* **트랜잭션:** ACID 원칙 (원자성, 일관성, 고립성, 지속성) 보장
* *원자성:* 전부 실행되거나 전부 실패
* *일관성:* 트랜잭션 후 DB 상태 일관성 유지
* *고립성:* 트랜잭션 간 영향 최소화
* *지속성:* 성공한 트랜잭션 영구 저장
* **검색:**
* **SQL (Structured Query Language):** 데이터 정의, 조작, 제어에 사용
* **`SELECT` 문:** 데이터 검색
* **`WHERE` 절:** 정확한 조건 필터링 (예: 작성자 이름, 나이, 가격 범위)
* **JOIN 연산:** 여러 테이블을 조합하여 조회 (예: 고객-주문, 주문-제품)
* **인덱싱 (B-tree, Hash):** 검색 성능 향상 (특정 값 빠른 검색)
* **장점:**
* 데이터 무결성 및 일관성 보장
* 표준화된 SQL 사용으로 접근 용이
* 정형 데이터 관리에 매우 효과적
* 성숙한 기술, 풍부한 생태계
* 복잡한 관계 표현 및 여러 테이블 연결 가능
* **단점 (생성형 모델 활용 시):**
* 비정형 데이터 (텍스트, 이미지) 처리 어려움
* 의미 기반 검색의 한계
* 대규모 데이터에서 수평적 확장 어려움
* 유연하지 못한 스키마 변경
* **활용 사례:** 온라인 서비스, 은행 시스템, 예약 시스템, 고객 관리, ERP, 전자상거래, 인사/급여 관리 등
* **주요 제품:** Oracle, MySQL, MariaDB, PostgreSQL, SQLite 등
## 3. 벡터 데이터베이스 (Vector DB)
* **정의:** 비정형 데이터 (텍스트, 이미지, 비디오 등)를 벡터 임베딩하여 효율적으로 저장, 관리, 검색하는 특화 DB
* **인베딩 (Embedding):** 단어를 다차원 공간에 벡터로 표현하여 의미적 유사성을 수치화
* 밀집 벡터 (Dense Vector): 숫자로 구성된 벡터
* **주요 특징:**
* **의미 기반 검색:** 데이터의 유사성을 기준으로 검색
* **비정형 데이터 처리:** 텍스트, 이미지, 비디오 등
* **핵심 기능:**
* **쿼리 벡터와 유사한 벡터 검색:** 고차원 공간에서의 빠른 유사도 검색 성능이 중요
* **유사도 측정:** 코사인 유사도, 유클리드 거리, 내적 등
* **Nearest Neighbor Search (ANN):** 정확한 최근접 이웃 검색보다 빠른 속도로 유사한 이웃 탐색 (근사치)
* **데이터 구조:**
* **벡터 임베딩:** 고차원 숫자 배열
* **메타데이터:** 벡터와 관련된 부가 정보 (유연한 구조 지원)
* **주요 기능:**
* **유사도 검색:** 쿼리 벡터와 DB 벡터 간의 거리/유사도 계산, 상위 k개의 벡터 반환
* **벡터 특화 인덱싱:** 그래프 기반, 클러스터링 기반, 해싱 기반, 벡터 압축 기반 등
* **확장성 및 일관성:**
* 수평적 확장이 용이
* 최종 일관성 허용 (강한 일관성보다)
* **장점:**
* 비정형 데이터의 의미 기반 검색 탁월
* 대규모 데이터셋의 고속 유사성 검색
* AI 모델과의 연동 용이
* 추천, 검색, RAG 등 다양한 AI 응용 지원
* **단점:**
* 정확한 값 매칭에는 비효율적
* 복잡한 관계형 쿼리 지원 약함
* 트랜잭션 기능 RDBMS보다 약함
* 상대적으로 새로운 기술, 생태계 발전 중
* 임베딩 모델 성능에 검색 품질 의존
* **활용 사례:** 추천 시스템 (상품, 뉴스, 비디오), 지식 검색, 이미지/비디오 검색, 챗봇, 가상 비서, 금융 사기 탐지 등
* **대표 제품:** Pinecone, Milvus, Chroma, Weaviate 등
## 4. RDBMS vs. 벡터 DB 비교
| 구분 | RDBMS | 벡터 DB |
| :------------- | :-------------------------------------------- | :----------------------------------------------------- |
| **주요 데이터** | 정형 데이터 (테이블 형태) | 비정형 데이터 (텍스트, 이미지 등) |
| **검색 방식** | 정확한 키워드/조건 필터링 (`WHERE` 절) | 유사도 기반 검색 (거리 기반) |
| **데이터 처리** | 정형 데이터 저장 | 임베딩된 고차원 벡터 데이터 저장 |
| **스키마** | 엄격함 | 유연함 (벡터 + 메타데이터) |
| **관계 표현** | 명시적 조인 | 암묵적 유사성 (거리 기반) |
| **확장성** | 수직 확장 중심 | 수평 확장 용이 |
| **주요 용도** | 정확한 값 조회, 트랜잭션 처리, 데이터 무결성 관리 | 의미 기반 검색, 유사도 검색, AI 모델 연동, 추천 시스템 |
## 5. 검색 증강 생성 (RAG) 및 DB의 역할
* **LLM의 한계:**
* 환각 (Hallucination)
* 최신 정보 부족
* 정보 출처 불분명
* 특정 도메인 지식 부족
* **RAG의 역할:** LLM이 답변 생성 전, 외부 지식 소스에서 관련 정보 검색 및 참고하여 답변의 **정확성과 신뢰성** 향상
* **DB의 역할 (RAG에서):**
* **핵심:** 대규모 지식 소스를 효율적으로 저장하고 관련성 높은 정보를 빠르고 정확하게 검색
* **벡터 DB:** 의미 검색 엔진으로서 질문을 벡터로 변환, 유사 벡터 검색, 원본 정보 반환 (RAG 검색 품질 결정)
* **RDBMS:**
* 보조적 역할로 신뢰도 강화
* 메타데이터 필터링, 구조화된 정보 조회, 사용자 세션 관리 등에 활용
* 정확한 조건 검색 (예: 특정 기간, 특정 사용자) 필요 시 사용
## 6. 하이브리드 접근 방식
* **필요성:** 실제 비즈니스 환경에서 정형/비정형 데이터가 혼재하며, 정확한 조건 검색과 의미 기반 유사성 검색 모두 필요
* **구현 방식:**
1. **별도 DB 접근:** RDBMS와 벡터 DB 각각 구축 후 애플리케이션 레벨에서 접근
* **장점:** 각 DB의 전문성 활용
* **단점:** 시스템 구성 및 관리 복잡성 증가
2. **하이브리드 DB:** 하나의 시스템에서 SQL 쿼리와 벡터 유사도 검색 동시 지원
* **장점:** 통합 용이, 잠재적 고성능
* **단점:** 기술 성숙도, 벡터 종속성 우려
3. **RDBMS 확장 (PostgreSQL + pgvector):** RDBMS 환경에서 벡터 검색 기능 통합
* **장점:** 익숙한 환경에서 단순 통합
* **단점:** 대규모 벡터 검색, 확장성 한계
* **결론:** 두 기술의 장점을 합쳐 정확성과 의미적 활용을 모두 달성하여 신뢰 있는 답변 생성
## 7. API 호출 및 데이터 관리
* **문제점:** OpenAI API 등 외부 API 호출 시 중간 끊김 발생 가능성, 결과 관리의 번거로움
* **해결책 (Database 활용):**
* API 응답 결과를 데이터베이스에 **순차적으로 업데이트**하며 관리
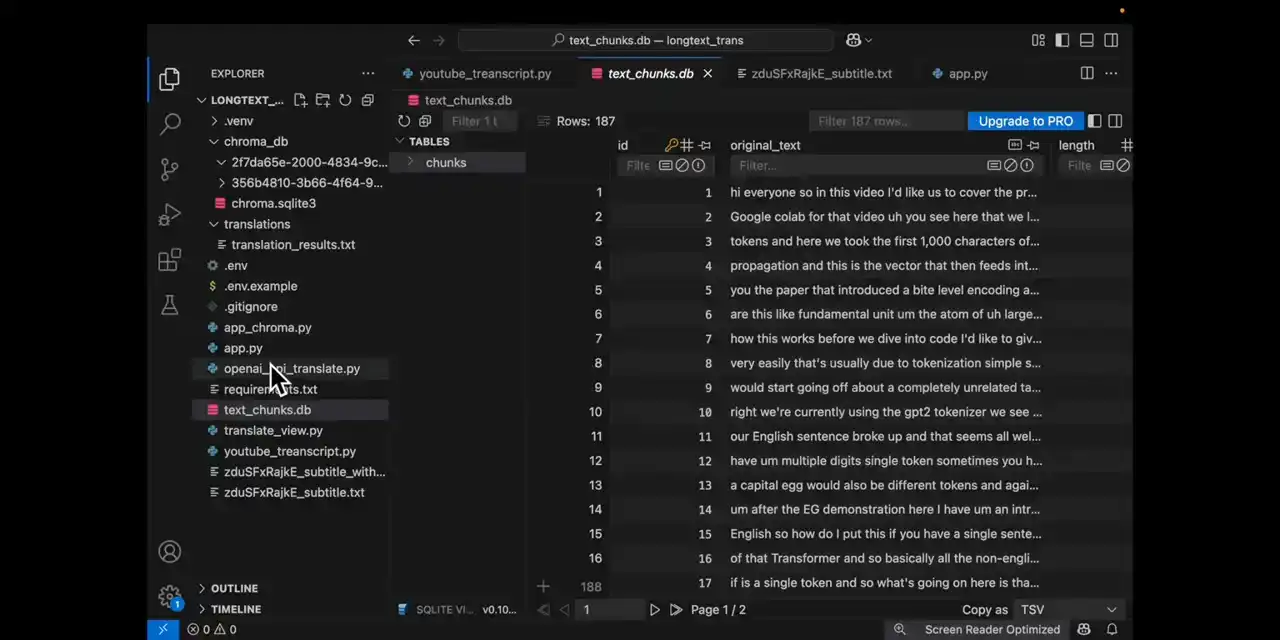
* **SQLite:** Python 내장 DB로 별도 설치 없이 사용 가능
* 원본 텍스트 저장 후, API 응답 결과 (번역 내용 등)를 해당 레코드에 업데이트
* **효과:**
* API 비용 효율화
* API 호출 관리 효율성 증대
* 중간 끊김 발생 시 미번역 구간부터 재요청 가능
* API 호출 진행 상황 명확히 파악 가능
## 8. 긴 텍스트 번역 및 관리 (실습 예시)
* **상황:** 안드레이 카파시의 긴 유튜브 영상 자막 번역
* 기존 방식: 긴 텍스트를 그대로 API에 전달 시 토큰 수 제한으로 번역 오류 또는 요약 결과 발생
* **벡터 DB 활용 방안:**
1. **자막 수집:** 유튜브 영상 자막 데이터 수집
2. **API 호출 (청크 단위):** OpenAI API 등을 활용하여 텍스트를 청크(chunk) 단위로 잘라 번역
* **주의:** 청크 방식에 따라 맥락 손실 발생 가능 (문단, 의미 단위 청크 권장)
3. **DB 저장 및 관리:**
* **SQLite:** 원본 텍스트와 번역 결과 업데이트
* **Chroma DB (벡터 DB):** 번역된 텍스트를 벡터화하여 저장
4. **질의응답:** 번역된 내용을 벡터 DB에 저장 후 "토큰화란 무엇인가?"와 같은 질문 시 관련 정보 검색 및 답변 생성
---
*본 문서는 원본 텍스트를 바탕으로 가독성 높게 재구성되었습니다.*