[KOR][30]New-GPU-Profiler-and-RHI-Submission-Pipe
https://m.youtube.com/watch?v=vnbARZHccpQ

에픽의 RHI 팀에서 Principal Rendering Programmer로 일하는 Luke Thatcher입니다. 함께하게 되어 감사합니다.

이것은 새로운 GP profiler와 RHI submission pipeline에 대한 세션입니다.

이번 세션은 크게 두 부분으로 나누어 진행하겠습니다. 첫 번째로는 Unreal 5.6의 새로운 GP profiler에 적용된 개선 사항들을 소개합니다.
두 번째 부분에서는 RHI submission pipeline에 대한 심도 있는 기술적 분석을 진행합니다. 이는 5.5 버전에서 선보였으나 아직 공개적으로 다루지 않았던 내용입니다. RHI는 Render Hardware Interface의 약자로, 렌더러와 GPU 플랫폼 API 사이에 위치하는 엔진 모듈을 의미합니다.

각 플랫폼별로 하나의 Render Hardware Interface(RHI)를 구현하며, 이것이 그래픽스 플랫폼 지원을 제공합니다.

GPU 큐에 대한 간략한 복습을 먼저 진행하겠습니다. 이는 이후 내용을 이해하는 데 중요한 배경이 될 것입니다.

프로파일러에 적용된 일부 변경사항에 대해 말씀드리고자 합니다. 이미 익숙하신 부분도 있겠지만, 간략하게 복습하는 시간을 갖는 것이 유익할 것이라 생각합니다.
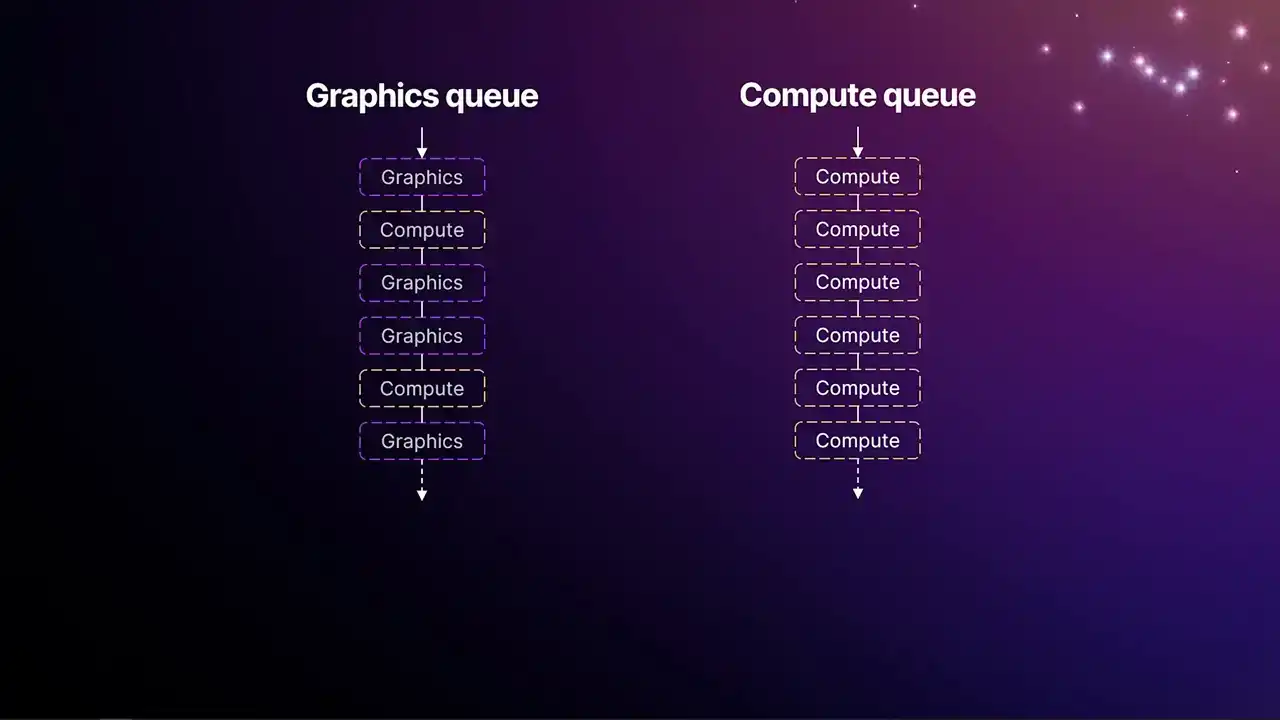
지난 10년간 GPU는 여러 큐(queues)를 갖추고 있습니다. 이는 CPU의 하이퍼스레딩(hyperthreading)이나 멀티스레딩(multithreading)과 유사하게, 애플리케이션이 GPU에 제출할 수 있는 두 개 이상의 독립적인 작업 큐를 의미합니다. 이 큐들은 동시에 실행되며 GPU의 실행 리소스를 지능적으로 공유합니다. 일반적으로 단일 그래픽스 큐(graphics queue)가 존재하며, 이 큐는 뎁스/스텐실 테스트, 버텍스/픽셀 셰이더 등 기존의 전체 래스터화 파이프라인(rasterization pipeline)에 접근할 수 있습니다.

이를 통해 compute job을 실행할 수도 있습니다. 일반적으로 compute shaders만 실행할 수 있는 하나 이상의 compute queue를 사용하게 됩니다. 이 queue에 제출되는 job들은 다음과 같습니다.
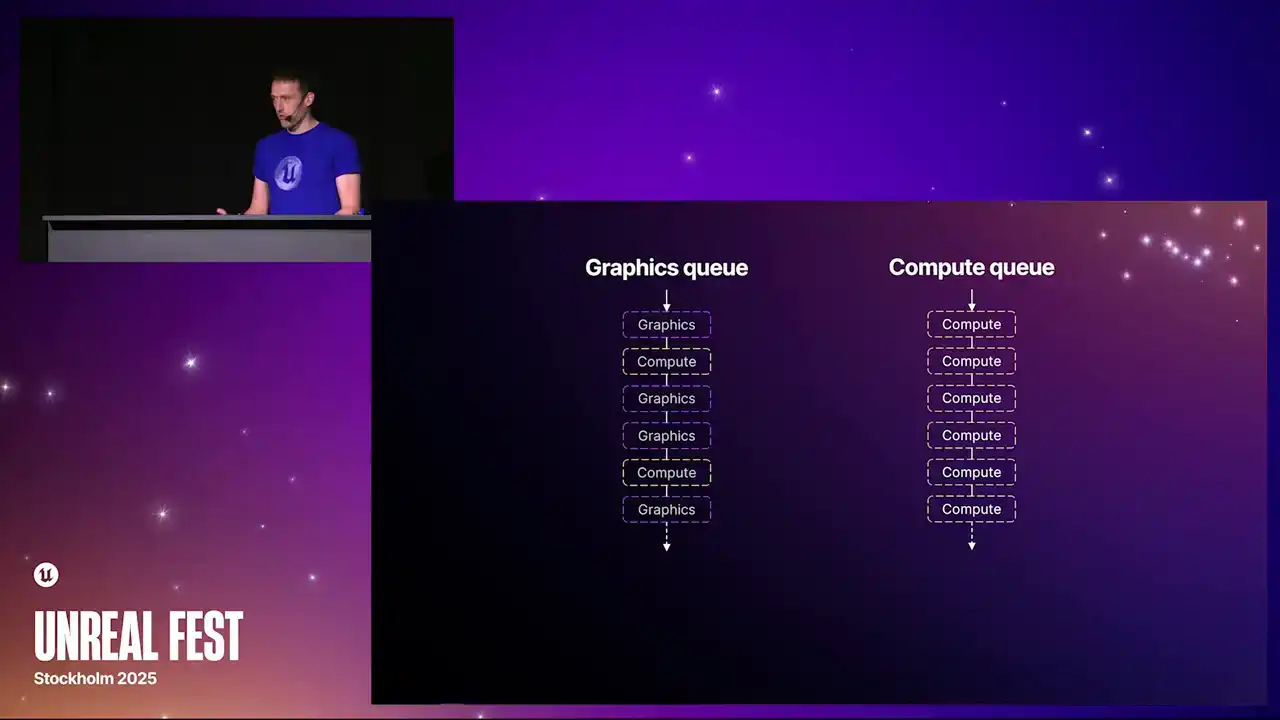
각 큐(queue)는 동시 실행될 수 있으나, 이는 항상 바람직한 것은 아닙니다. 한 큐에서 생성된 데이터를 다른 큐에서 소비해야 하는 경우, 두 큐 간의 동기화 방법이 필요합니다. 여기서 'fence'가 사용됩니다. Fence는 한 큐가 다른 큐로부터 데이터 생성 완료 신호(signal)를 받기 전까지 더 이상 진행하지 못하도록 하는 동기화 프리미티브(synchronization primitive)입니다.
이 경우, 오른쪽의 세 가지 compute job은 왼쪽 상단의 graphics 큐 작업이 완료되기 전까지 시작할 수 없습니다. fence A 신호가 전달되고, fence A를 대기함으로써 모든 작업이 진행될 수 있습니다. 반대로, graphics 큐의 마지막 세 가지 job은 compute 큐의 신호가 전달되기 전까지 시작할 수 없습니다. 이러한 대기(wait)는 큐를 지연시키므로, 이것이 흥미로운 점입니다.

실행이 일시 중지될 수 있으며, 이는 좌측에서 `wait for fence B` 직전의 간격을 통해 확인할 수 있습니다. 큐들이 서로 동기화되기 때문입니다.

프로파일러를 살펴볼 때 큐(queues)에 이러한 종류의 버블(bubbles)이 발생할 수 있다는 점을 염두에 두시는 것이 중요합니다.

GPU 프로파일러와 5.6 버전에서의 개선 사항에 대해 말씀드리겠습니다. 이 도구들에 익숙하시기를 바랍니다. GPU 프로파일러의 주요 구성 요소는 stat GPU, profile GPU command, 그리고 Unreal Insights입니다. 5.6 버전에서는 RHI breadcrumb 시스템을 기반으로 이 도구들을 처음부터 다시 구축했습니다. RHI breadcrumb 시스템에 대해서는 이어서 설명드리겠습니다. 핵심적인 변화는 모든 도구가 이제 통합된 데이터 소스에서 정보를 가져온다는 점입니다. 이로 인해 이전 버전에서 발생했던 밀리초 단위의 미세한 수치 불일치가 해소되어 모든 도구가 일관된 결과를 보여줍니다.
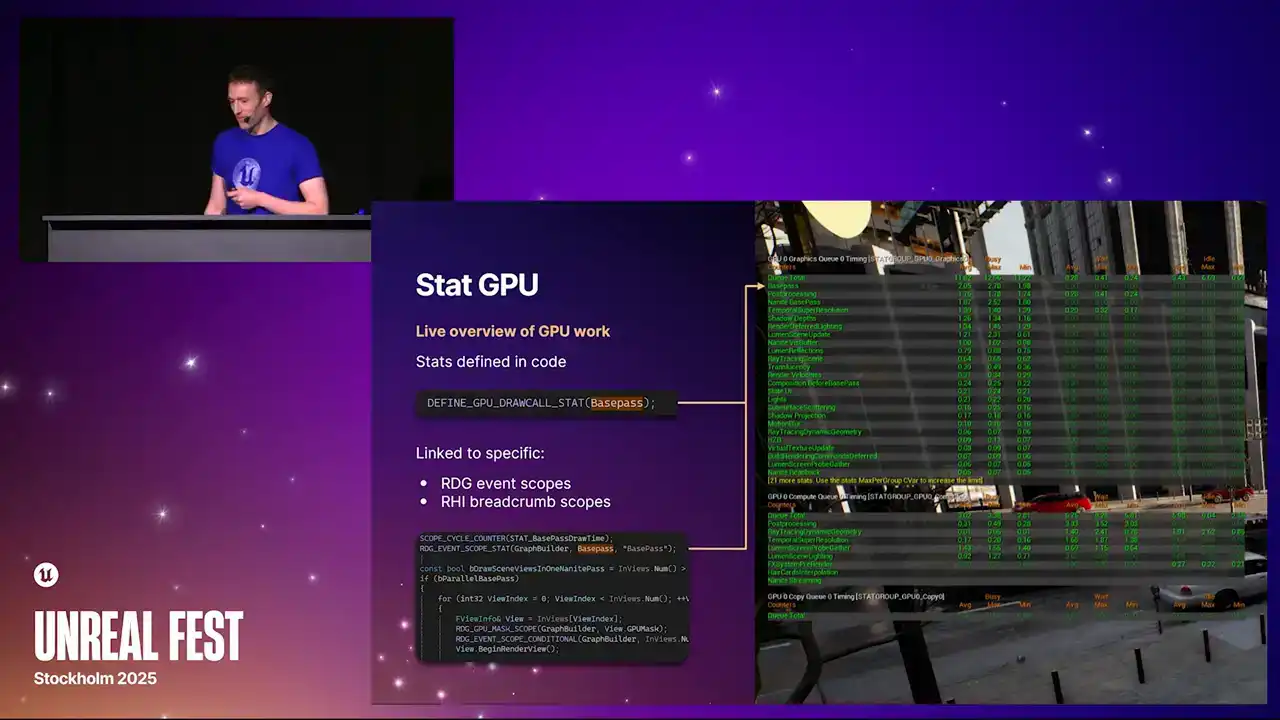
statGPU는 GPU 작업에 대한 실시간 개요를 제공하는 툴입니다. 콘솔과 에디터 모두에서 사용할 수 있으며, 각 줄은 하나의 stat을 나타냅니다. 이 stat들은 defining code이며, 예를 들어 base pass를 위한 매크로가 있습니다. 개별 stat은 특정 render graph event scope 또는 RHI breadcrumb scope에 연결됩니다. 해당 scope 내에서 발생하는 모든 렌더링은 이 stat에 귀속됩니다. stat은 렌더러 내에서 여러 번 나타날 수 있으며, 예를 들어 post-processing stat은 렌더러의 여러 위치에서 태그될 수 있습니다.

그리고 'stat GPU'에서 보이는 stat, 즉 데이터는 이를 합친 것입니다. 따라서 어떤 결과를 축적하게 됩니다.
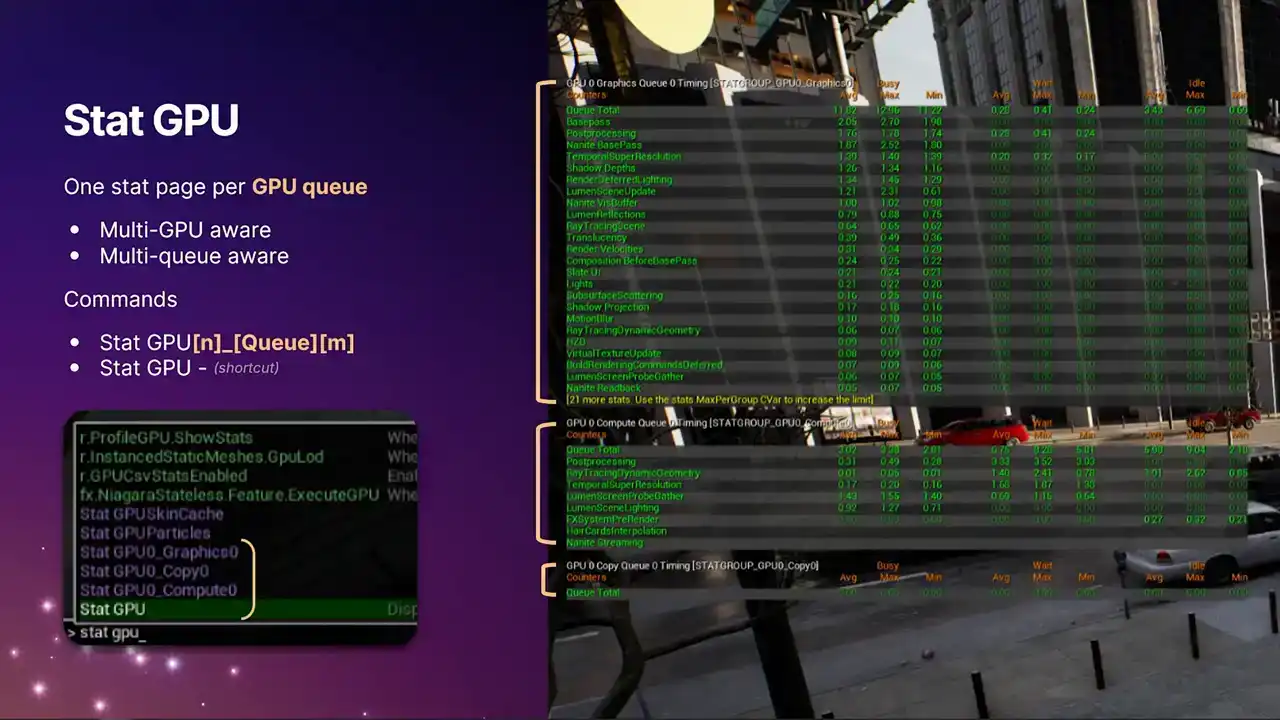
5.6 버전에서 가장 큰 변화는 Multi GPU 및 Multi Queue를 지원하게 된 점입니다. 이전에는 `stat GPU` 명령어로 첫 번째 GPU의 단일 그래픽 파이프라인 정보만 확인할 수 있었습니다. 따라서 Asynchronous Compute를 실행하더라도 해당 작업의 정보는 전혀 볼 수 없었습니다.
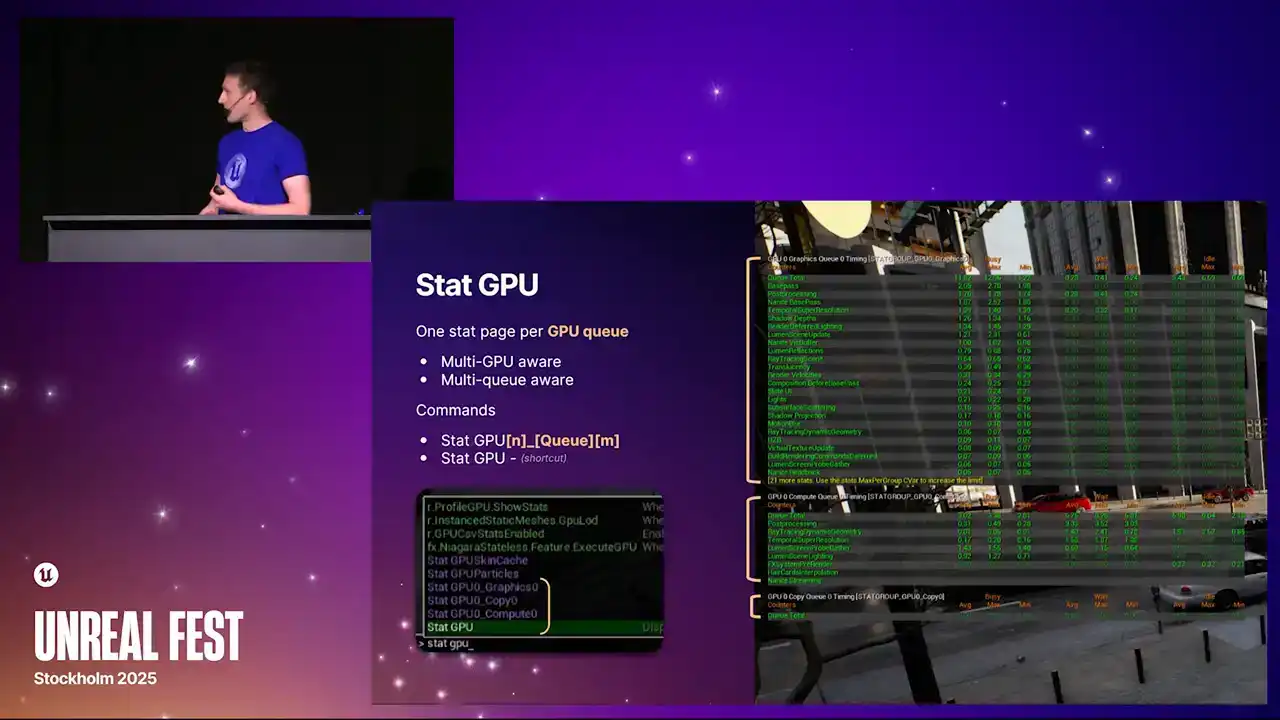
가상 프로덕션(virtual production) 환경에서 여러 GPU를 사용하는 경우에도 GPU 관련 정보를 얻을 수 없었던 문제가 해결되었습니다. 이제 모든 GPU 정보를 확인할 수 있습니다. 각 통계 페이지는 대괄호로 강조 표시되어 있습니다.

이들은 모두 독립적인 stat 페이지입니다. 표준 Unreal stat 시스템을 사용하며, `stat GPU`와 같은 긴 형식의 명령어를 사용하여 개별적으로 불러올 수 있습니다. 여기에 queue type과 추가적인 index를 지정할 수 있습니다.
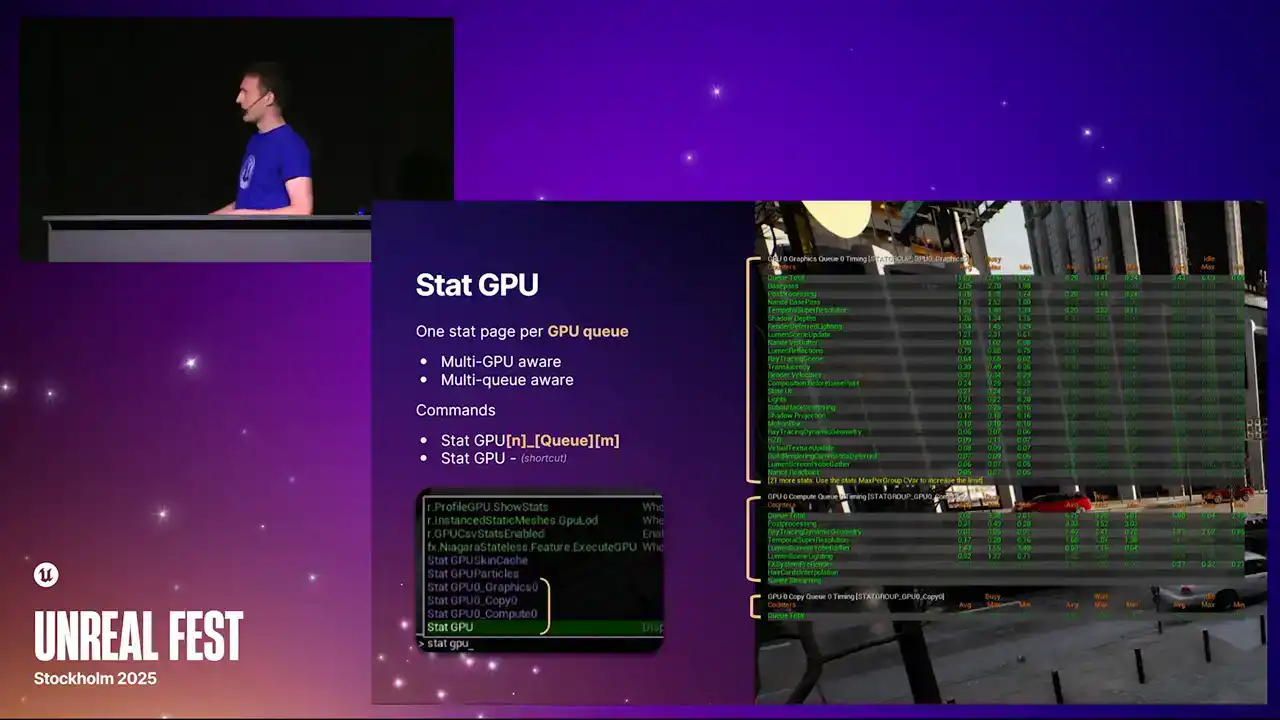
향후 여러 compute queue를 지원할 수 있도록 구축되었습니다. 현재는 하나만 지원하지만, 표준 stat GPU command를 재활용하여 매크로처럼 모든 기능을 켜고 끄도록 변경했습니다. statGPU를 입력하는 습관이 있으시다면 이전과 동일하게 작동할 것입니다.
하지만 현재 제공되는 실제 데이터는 크게 확장되었습니다. 이제 세 개의 별도 컬럼으로 데이터를 확인할 수 있습니다. 가장 왼쪽에 있는 컬럼은 이전에 보셨던 것으로, GPU가 명령 리스트나 셰이더를 실행하며 실제 유용한 작업을 수행한 'busy time'을 나타냅니다.

오른쪽 중간 열에는 새로 추가된 두 가지 항목이 있습니다. 이 중간 열은 대기 시간(wait time)을 나타냅니다. 다시 한번 앞에서 설명드렸던 예시를 떠올려보면,
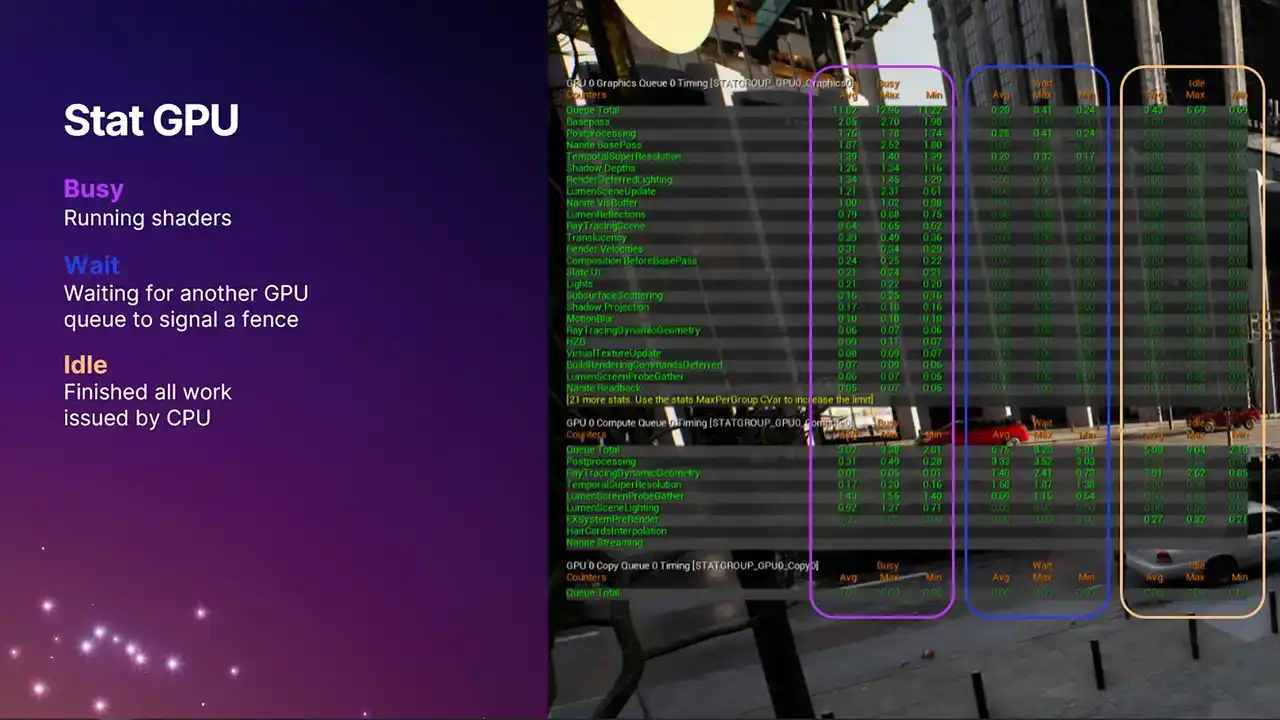
이 시점에서는 하나의 큐가 다른 큐의 signal을 기다리느라 유용한 연산을 수행하지 못하고 있습니다. Compute 큐에서는 일반적으로 0이 아닌 값이 더 크게 나타날 수 있습니다. 이는 Graphics 큐와의 연관성에 따라 Compute 큐에서 항상 이득이 되는 연산을 수행하는 것은 아니기 때문입니다. Compute 큐 상의 프레임 일부는

컴퓨트 큐(Compute Queue)에서 많은 대기 시간(wait time)이 관찰된다는 것은 반드시 부정적인 상황만을 의미하지 않습니다. 해당 작업이 fences signaling을 기다리거나 data dependencies가 resolve되기를 기다리는 idle 상태일 수 있습니다.
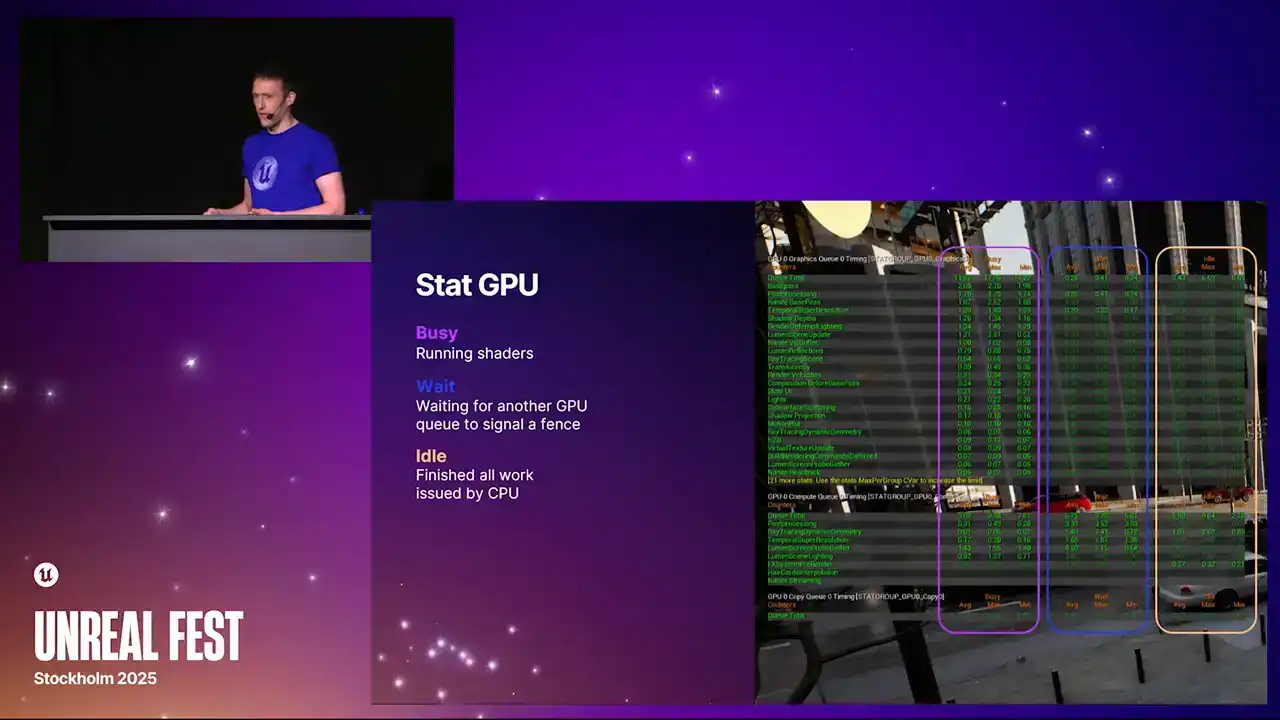
그래픽스 큐(graphics queue)는 항상 바쁘게 유지하려고 노력합니다. 따라서 일반적으로 해당 수치는 0에 가까워야 합니다. 오른쪽에 있는 열은 유휴 시간(idle time)을 나타냅니다. 언리얼 엔진에서 이러한 통계는 이전에는 볼 수 없었던 매우 흥미로운 기능입니다. 작업이 언제 제출되는지 정확하게 파악할 수 있기 때문입니다. D3D12와 같은 최신 API에서는 드라이버에 작업이 언제 제출되는지 정확하게 알 수 있습니다.

GPU의 작업 완료 시점을 정확히 파악할 수 있습니다. CPU로부터 더 이상의 작업을 받지 못해 GPU가 Idle 상태가 된 것을 확인할 수 있습니다. 여기서 0이 아닌 값은 GPU가 모든 작업을 완료했으며, CPU에서 추가 작업을 제공하지 않아 Idle 상태가 되었음을 의미합니다. 이는 귀하의 타이틀이 적어도 부분적으로는

해당 프레임 동안 CPU bound 현상이 발생합니다. 여기에 0이 아닌 값이 보인다면, 테스트 빌드 또는 CPU 성능이 우수한 환경에서 실행하고 있는지 확인하시기 바랍니다. 그렇지 않다면 해당 값은 대표성이 떨어진다고 볼 수 있습니다. 만약 0이 아닌 값이 관찰된다면, Unreal Insights 또는 다른 툴을 사용하여 추가적인 조사가 필요합니다.
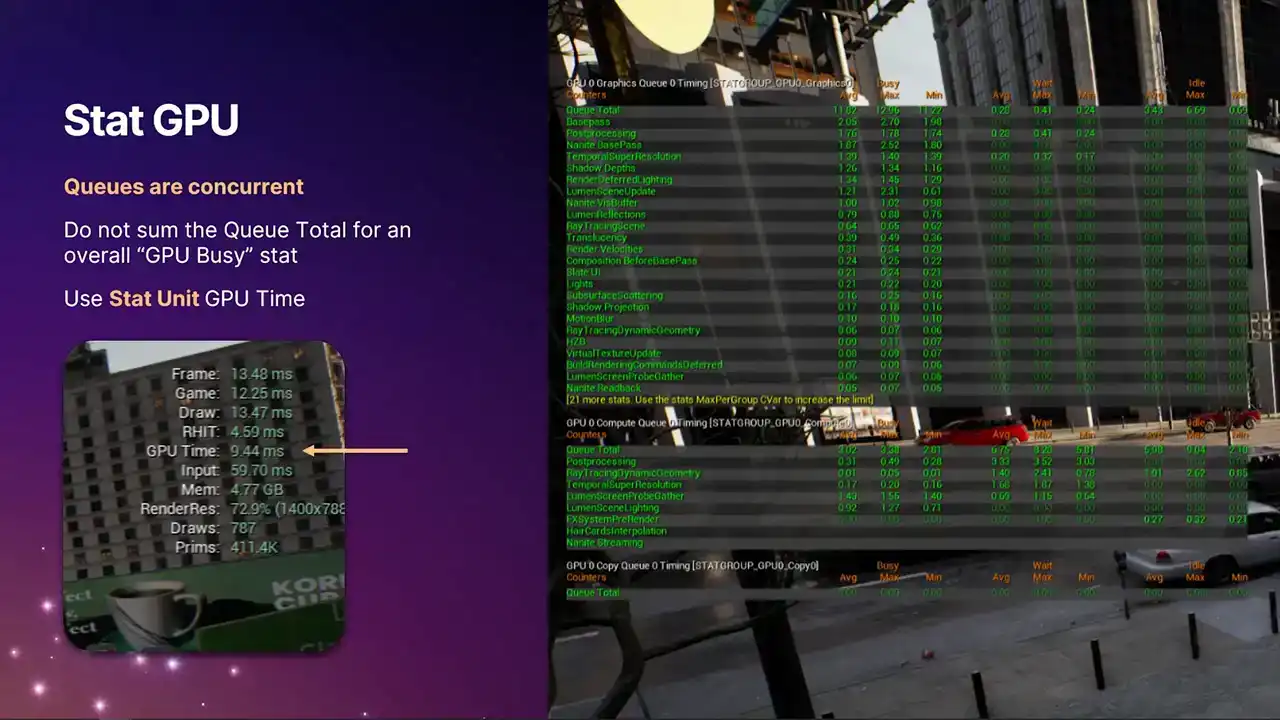
큐(queue)들이 동시적(concurrent)이므로, 각 큐 페이지의 수치를 단순히 더하는 것은 의미가 없습니다. 각 통계 페이지에는 프레임당 특정 열의 총 작업량을 나타내는 큐 총계(queue total)가 있습니다. 그러나 전체 프레임에 대한 GPU 시간을 대략적으로 파악하려면, 화살표로 표시된 GPU 시간(stat GPU time)을 사용해야 합니다.
이 GPU 시간 통계는 모든 큐에서의 바쁜 시간(busy times)을 합집합(union)하여 계산됩니다. 이 값은 프레임 전체의 최종 통계 시간으로 사용되며, 이는 동적 해상도(dynamic resolution)와 같은 시스템을 구동하는 데 활용됩니다.

이 프레임에서 GPU 비용을 나타내는 단일 stat이 필요하기 때문입니다. 이를 통해 여러 사항을 확장하거나 축소할 수 있습니다. 계속해서 Profile GPU로 넘어가면, 이미 보셨을 수도 있습니다.
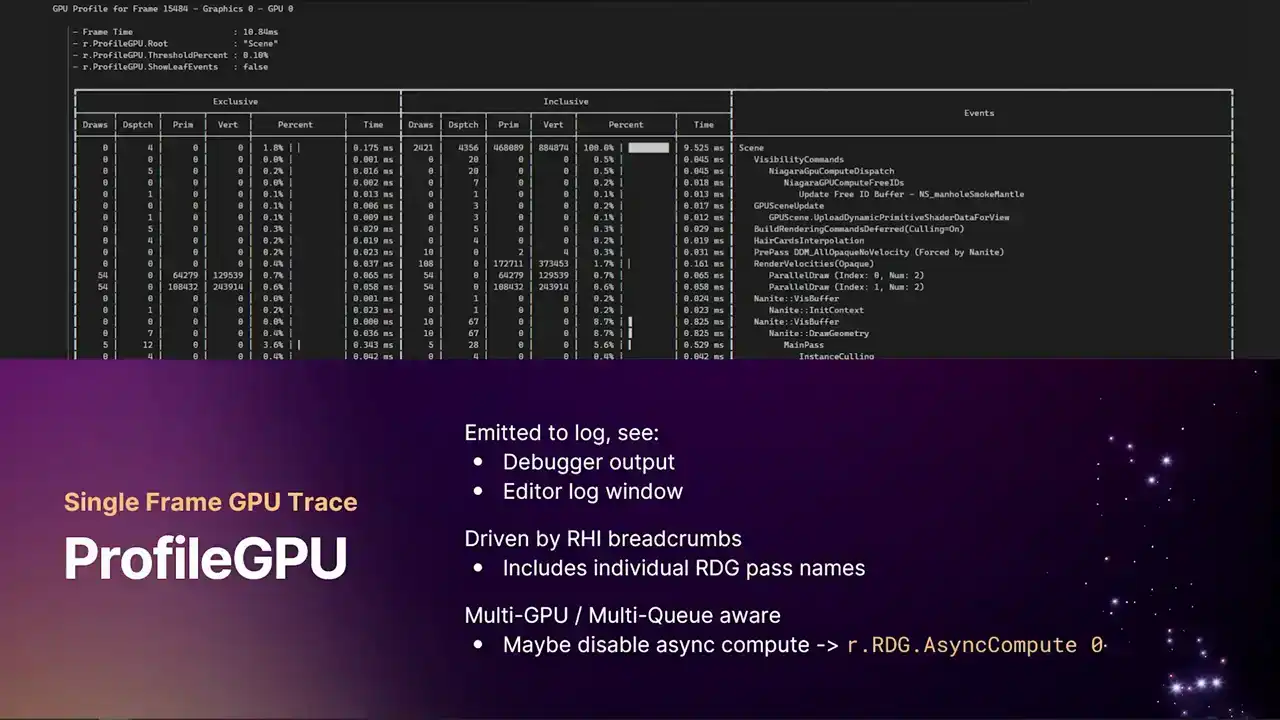
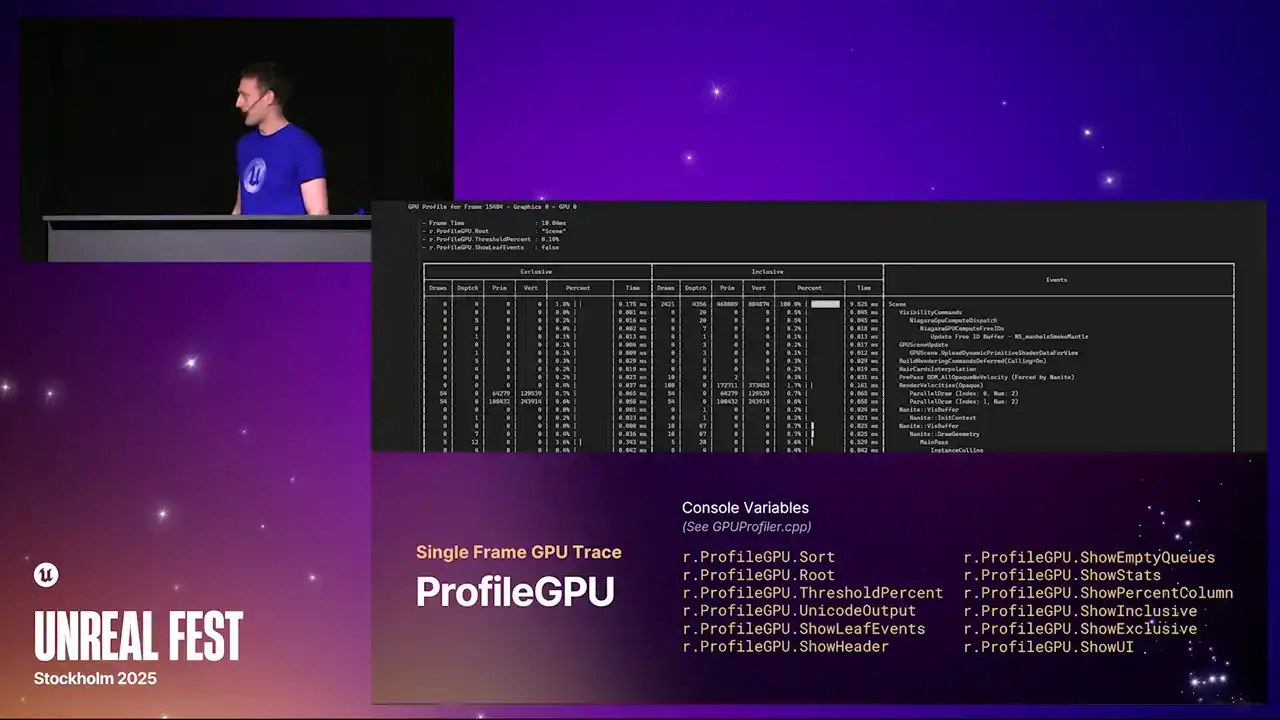
이전에 보셨을 명령어입니다. 게임 내 콘솔에서 실행할 수 있는 명령어로서, 텍스트 로그를 생성하여 UE log로 내보냅니다. Visual Studio가 연결되어 있다면 디버거 출력 창으로, 혹은 에디터 로그 창이나 로그 파일 자체로 기록됩니다. 해당 프레임에서 발생한 모든 일들을 테이블 형태로 깔끔하게 보여주는 뷰를 제공합니다. 이는 추후 설명드릴 RHI breadcrumb system에 의해 구동되며, 모든 개별 RDE pass 이름을 포함합니다. 이 명령어를 사용하는 데는 몇 가지 방법이 있습니다. 저는 특정 pass가 실행되고 있는지 확인하기 위해 가끔 이 명령어를 사용합니다. 콘솔에 간단히 입력하기에 아주 유용한 명령어입니다.

출력 로그를 보시면, 현재 프레임에서 특정 post-process pass가 실행되고 있음을 확인하실 수 있습니다. 물론, 모든 stat breakdowns 정보도 제공됩니다. 이제 처음으로 exclusive 및 inclusive timings을 모두 표시합니다.
이전에는 Inclusive Timings만 보여드렸으나, 이번 업데이트를 통해 Multi-GPU 및 Multi-Queue에 대한 지원이 추가되었습니다. 각 GPU와 큐마다 별도의 테이블이 생성됩니다. Async Compute가 활성화된 경우, 그래픽과 컴퓨팅을 위한 두 개의 테이블이 제공됩니다.

특정 렌더 패스나 셰이더 최적화 및 튜닝을 위해 이 툴을 사용하고자 하신다면, Cvar `r.rdg.async_compute 0`을 통해 async compute를 비활성화하는 것이 가장 좋을 수 있습니다.
이러한 현상은 compute 작업과 graphics queue 작업이 실행 리소스를 공유하며 서로의 타이밍에 영향을 주기 때문에 발생합니다. 특정 pass에 집중하고자 한다면 해당 기능을 비활성화하는 것이 유용합니다. 이 기능을 끄면 모든 작업이 graphics queue로 재정렬되어 동기화됩니다.
이 테이블을 필터링하고 불필요한 컬럼을 숨기는 데 사용할 수 있는 다양한 console variable이 존재합니다. 현재 스크린샷 예시에서는 scene node만 표시하도록 tree를 필터링했습니다. 이는 `r.profileGPU.root` console variable을 사용하여 수행할 수 있으며, 문자열과 와일드카드를 사용하여 일치하는 event 이름만 표시할 수 있습니다. 예를 들어, post-processing에 집중하는 경우에 활용할 수 있습니다.

`post-processing`으로 라우트를 설정하시면 됩니다. 테이블에서 해당 부분만 보이게 됩니다. 또한, 일부 텍스트 편집기는 유니코드 고정 너비 문자를 잘 처리하지 못한다는 점을 유념하셔야 합니다. 따라서 현재 저희가 상대적 타이밍을 보여주기 위해 사용하는 예쁜 막대들은 일부 텍스트 편집기에서 제대로 표시되지 않을 수 있습니다.
해당 폰트는 이를 지원하지 않으며, 모두 정렬되지 않았습니다. 따라서 해당 문제를 발견하시면, 이러한 문자를 지원하는 폰트로 변경하는 것을 권장합니다.

그렇게 하면 보기 좋은 테이블 뷰를 얻을 수 있습니다. 그렇지 않으면 output cvar을 0으로 설정하면 ASCII 문자로 대체되며, 이때 테이블이 제대로 정렬됩니다.

Unreal Insights로 넘어가겠습니다. CPU 프로파일링을 위해 이 도구를 사용하고 계시기를 바랍니다. 이제 Unreal Insights의 GPU 기능이 크게 향상되었습니다. 앞서 말씀드린 대로, 저희는 이제 Multi-GPU 및 Multi-Queue를 인지합니다. 따라서 GPU당 큐마다 하나의 타임라인을 제공합니다.
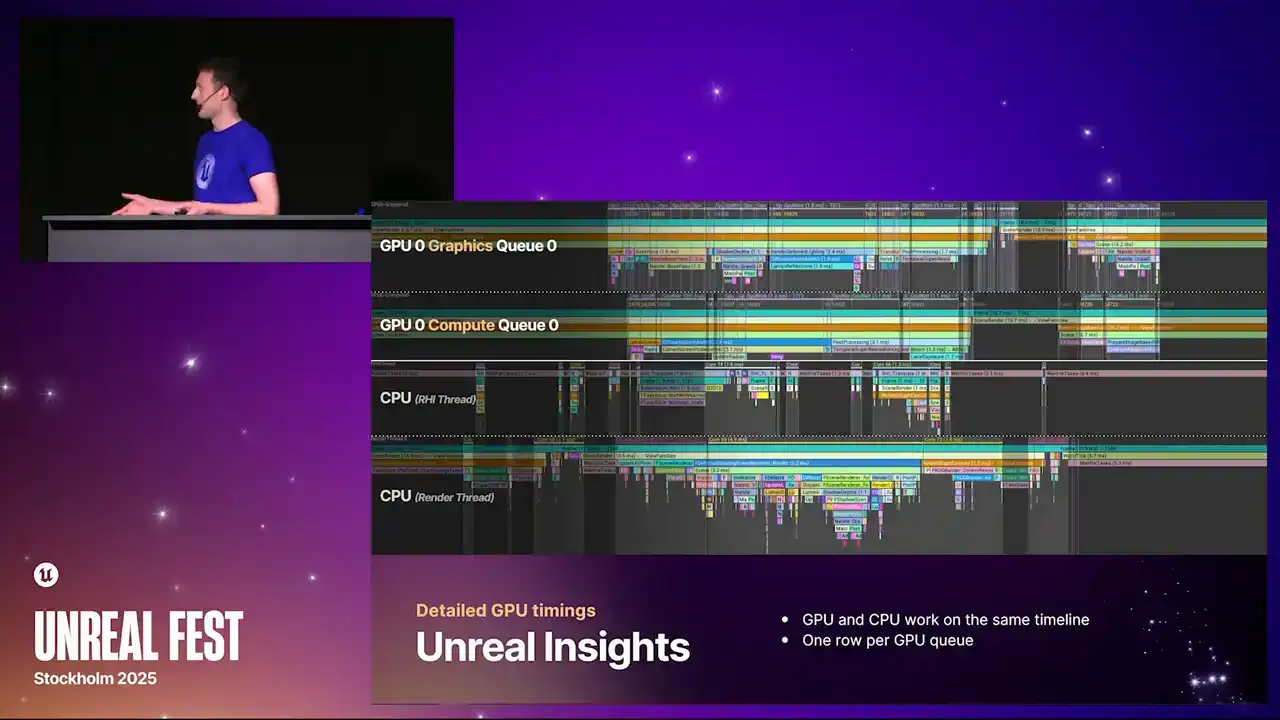
CPU와 GPU 간의 큐(queue) 정렬이 올바르게 되어 있음을 확인할 수 있습니다. 이를 통해 CPU에서 GPU로, 그리고 다시 CPU로 작업 흐름을 파악하고, 파이프라인(pipeline) 상의 병목(bubble) 발생 지점을 찾아낼 수 있습니다.

Unreal Insights에서 CPU 스레드의 context switch 데이터를 통해 스레드가 언제 스케줄링되고 실행되는지 확인하는 것에 익숙하신 분들이 계실 것입니다. 이제 GPU에서도 유사한 기능을 제공합니다. 새로운 프로파일러에서 얻는 추가 정보를 활용하여 큐가 언제 실행 중이고, 언제 대기 중이며, 언제 유휴 상태인지 정확하게 보여주는 리전을 그릴 수 있습니다.

타임라인 상단의 강조 표시된 영역은 현재 GPU Busy Work를 수행하는 구간을 나타냅니다. 이는 `stat GPU` 명령으로 얻을 수 있는 통계와 동일한 정보를 보여주며, 해당 구간들의 합산으로 데이터가 생성됩니다.
이곳에서 강조 표시된 영역은 큐가 차단된 GPU Weight 영역입니다. 아래쪽 라인은 Async Compute Queue를 나타내며, Async Compute의 일반적인 작동 방식 때문에 해당 큐에서 더 많은 Weight Work이 발생하는 것을 볼 수 있습니다.
마지막으로, 위에 아무런 표시가 없는 회색 영역은 Idle 영역, 즉 GPU가 유휴 상태인 구간을 의미합니다.

GPU가 더 이상 처리할 작업이 없어 멈춘 상태입니다. CPU에서 새로운 작업 지시가 내려오지 않았기 때문입니다.
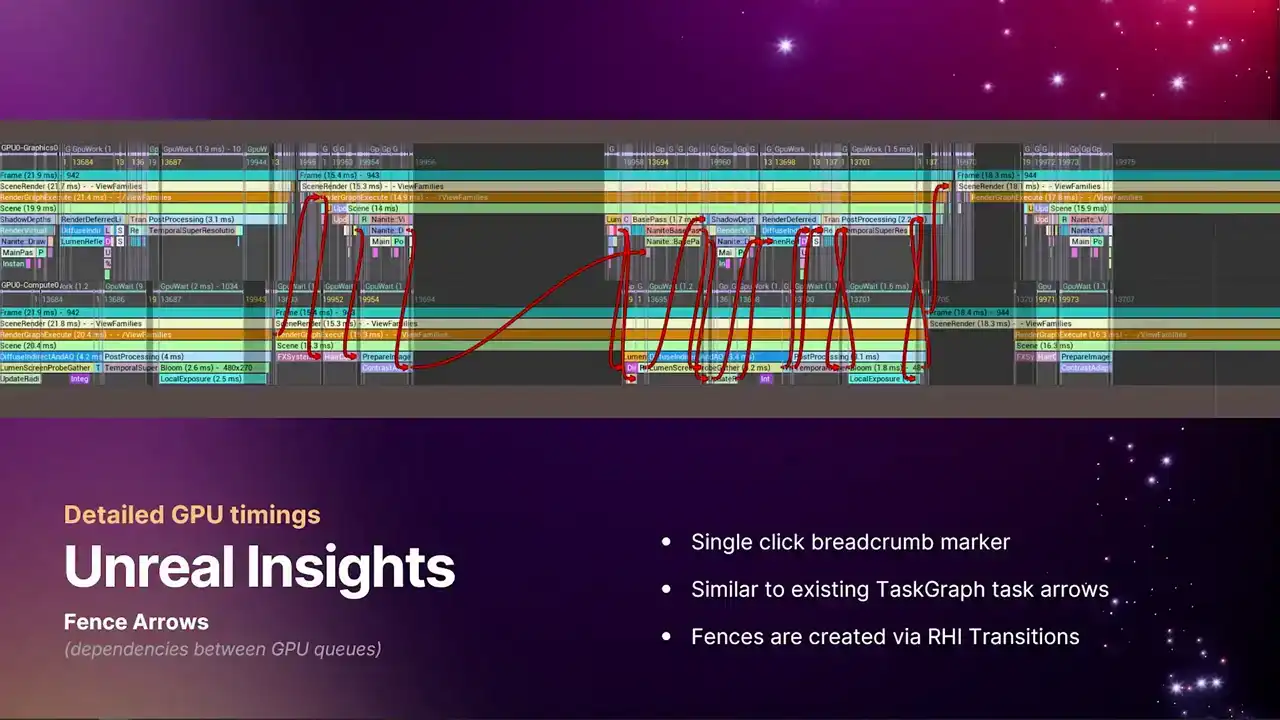
Unreal Insights의 CPU 작업(tasks) 채널과 유사하게, 이제 fence dependency arrow를 추가하였습니다. 이 기능은 프레임 마커와 같이 특정 마커를 클릭하면 활성화됩니다. 현재 화면에서는 프레임 마커를 클릭했을 때 나타나는 두 큐 간의 모든 대기(weight) 종속성을 보여줍니다. 각 화살표는 signal되고 대기(wait)되는 fence를 나타냅니다.

RHI transition API에 의해 구동되는 기능입니다. 일반 사용자가 직접 다룰 API는 아니며, RGG(Render Graph)가 이 모든 부분을 처리합니다. RGG는 특정 Pass 간의 데이터 종속성을 인지할 때 fences를 생성합니다. 현재 보이는 화면은 다소 복잡합니다. 따라서 확대하여 단일 예시를 살펴보겠습니다.

이 화살표들을 통해 타임라인에서 각 요소가 어떻게 표시되는지 정확히 파악할 수 있습니다. 위쪽 줄은 graphics queue이며, 아래쪽 줄은 compute queue입니다. 현재 몇 밀리초 동안 실행되고 있는 Nalite base pass 작업과, ASIN Compute Queue가 graphics queue를 기다리는 영역이 있습니다.
조금 더 확대해보면, 이는 앞서 본 화살표와 동일합니다. 왼쪽 상단 영역에서 graphics queue가 많은 작업을 처리하고 있음을 볼 수 있습니다. 이 busy work가 완료되는 즉시 fence 신호를 보냅니다.

이 두 개의 일치하는 fence number로 표시됩니다. 타임라인의 마커 바로 아래에 나타나며, 이는 특정 fence의 index입니다. pipe를 따라 단순히 증가하며, 최초로 제출된 fence는 index 1입니다. fence가 신호되는 정확한 위치를 보여줍니다.

fence가 정확히 일치하지 않을 수 있는 지점에서 fence가 어떻게 처리되는지에 관한 것입니다. fence는 훨씬 일찍 signal하고, 이후에 things가 정렬되는 방식에 따라 나중에 weighting될 수 있습니다.
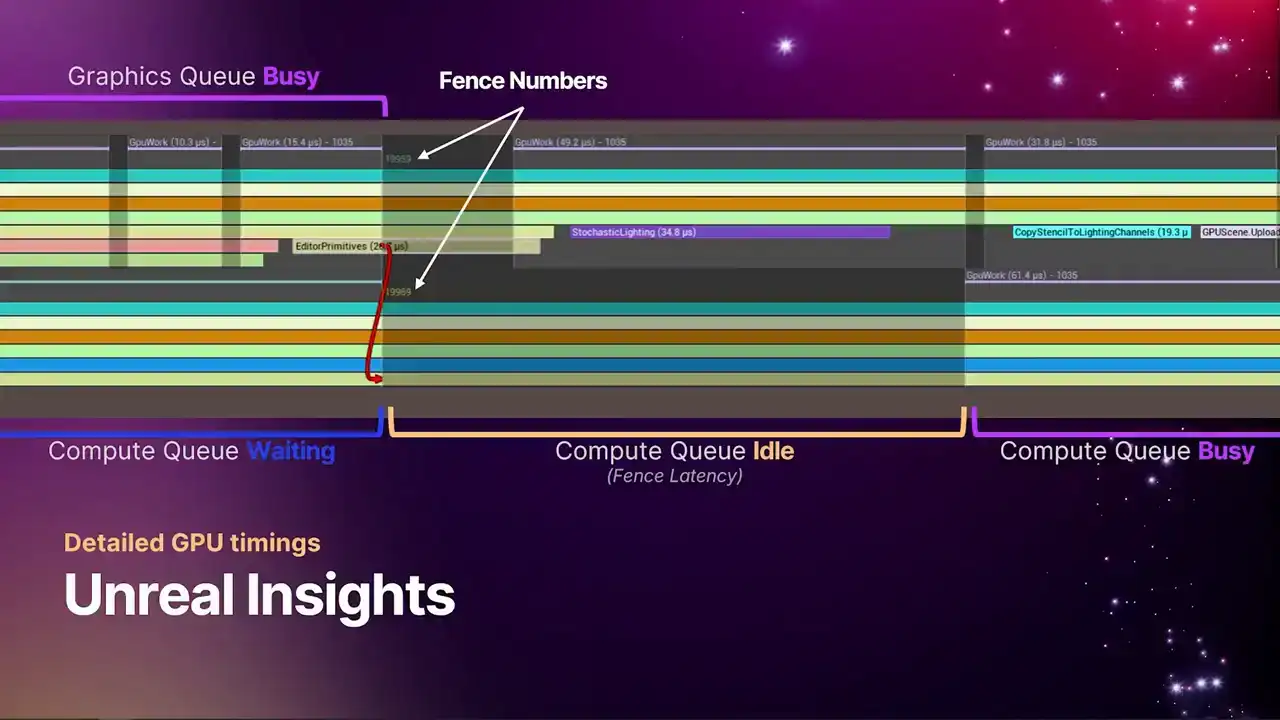
여기에서 보시는 바와 같이, fence가 signal됩니다. compute queue는 대기 상태에서 다시 idle 상태로 돌아갑니다. fence를 signal하는 데에는 항상 어느 정도의 latency가 수반되기 때문입니다. 하지만 아주 짧은 시간이 지나면, compute queue가 다시 활성화되어 GPU busy 상태로 돌아가는 것을 확인하실 수 있습니다.

CPU 타임라인과 인사이트가 GPU 큐와 올바르게 정렬됨에 따라 GPU 파이프라인으로 들어가는 데이터 흐름에서 많은 정보를 얻을 수 있습니다. 현재 대부분의 플랫폼 RHI(Render Hardware Interface)에는 RHI 제출 스레드가 있습니다. 이 스레드는 RHI 스레드와 GPU, 드라이버 사이에 위치하며, 주로 GPU 및 드라이버 오버헤드를 줄이기 위해 작업을 일괄 처리하는 데 사용됩니다. 이를 통해 OS 호출 횟수를 줄일 수 있으며, 펜스(fences)를 해석하는 역할도 담당합니다.

타임라인의 좌측 상단을 보시면, RHI thread와 RHI submit to GPU 마커가 있습니다. 이 마커는 렌더러의 CPU 스레드에서 처리된 작업을 GPU 제출 스레드로 넘겨주는 지점입니다.

Submission thread는 batching 작업과 fence resolving을 위해 일정 시간 동안 실행됩니다. 이후 우측의 파란색 영역에 도달하며, 이 시점에서 OS로 실제 호출이 이루어집니다. 그 직후 GPU queue가 즉시 활성화되는 것을 확인할 수 있습니다.
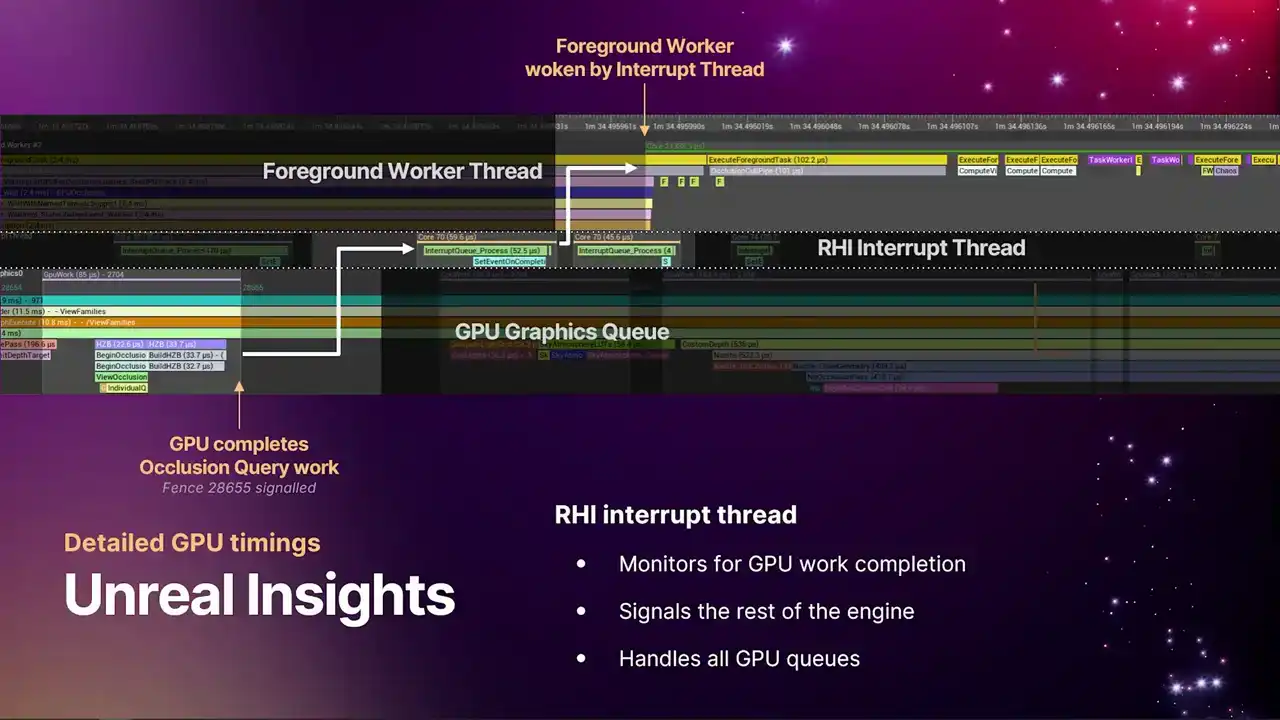
GPU로 작업이 전달되는 submission thread와 유사하게, GPU에서 작업 완료를 모니터링하여 엔진의 나머지 부분에 신호를 보내는 또 다른 thread가 있습니다. 이를 RHI interrupt thread라고 부릅니다. 이 thread는 기본적으로 fences에 대기하며 큐에 제출된 작업이 언제 완료되었는지 확인하고, 완료되면 엔진의 나머지 부분에 신호를 보냅니다. 일반적으로 이러한 thread는 하나만 존재하지만, 모든 GPU 큐를 처리합니다.
이 스레드는 큐(queue)의 작업 완료 시점에 활성화됩니다. 마치 생기가 돋는 것처럼요. 타임라인 예시에서 보이는 이 부분은 occlusion queries 입니다. 가장 왼쪽 하단에서 GPU가 이전 프레임에 대한 occlusion queries 를 수행하고 있는 것을 확인할 수 있습니다.
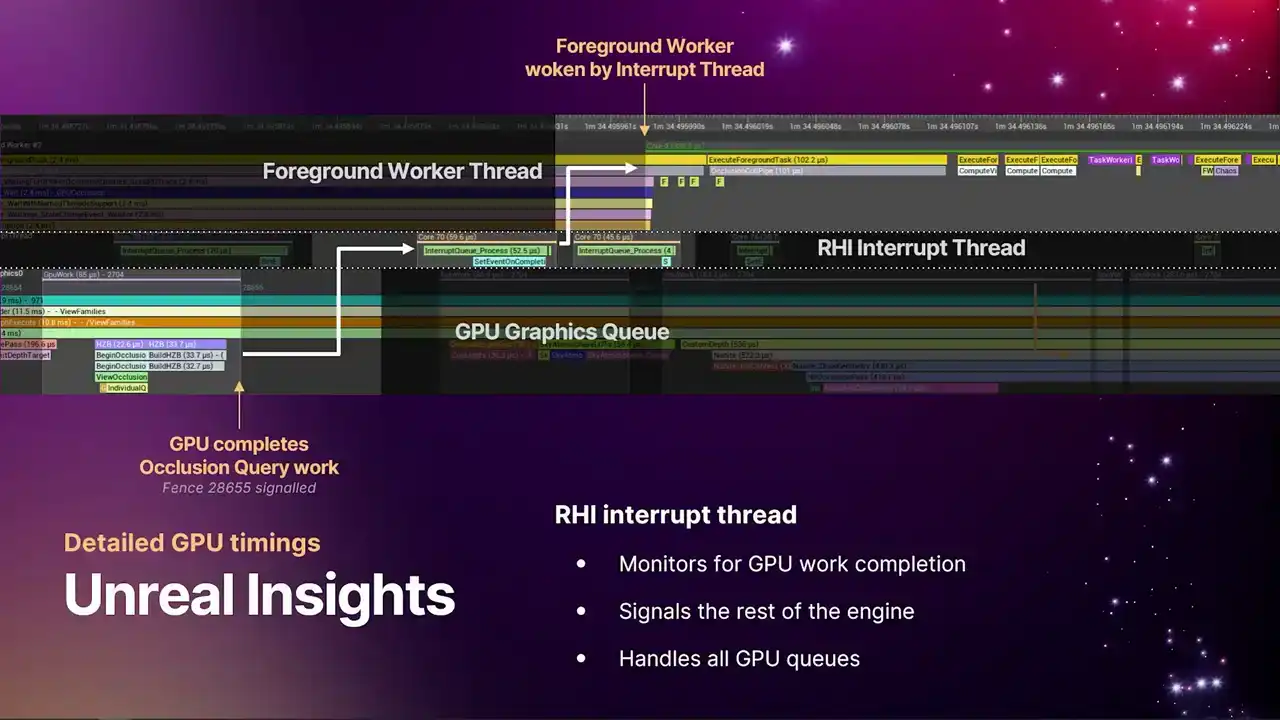
상단 우측의 foreground worker thread에서는 렌더러 코드가 scene visibility pass를 수행합니다. 이 pass는 해당 데이터를 필요로 하며, occlusion query 결과가 해당 프레임에서 완료되기를 기다리고 있습니다. GPU가 작업을 완료하면, event를 signal하며 fence number를 사용합니다.

슬라이드에서 직접적으로 보이지 않지만, 화살표가 가리키는 곳에서 Fence가 Resolve되며 Interrupt Thread를 깨웁니다. Interrupt Thread는 GPU 전체의 Queue를 탐색하여 완료된 작업을 파악합니다. 특정 작업이 완료되었음을 인지하고, 해당 작업을 가져옵니다.
해당 이벤트가 TaskGraph로 전달되어 TaskGraph를 활성화합니다. 이러한 데이터 흐름을 통해 RCHI submission thread, RCHI interrupt thread 및 timeline 정렬을 활용하여 Bottleneck과 Bubble을 정확히 파악하고, 파이프라인 전반에 걸친 분석을 수행할 수 있습니다.

GPU부터 렌더 스레드까지 이어지는 프로세스 전반에 걸쳐 개선이 이루어졌으며, 이는 매우 강력하고 유용합니다. 이것으로 새로운 프로파일러에 대한 개선 사항 설명을 마칩니다.

이제 5.5 버전에 적용된 저희의 새로운 RHI submission pipeline에 대해 말씀드리겠습니다.

본 섹션에서는 RHI API 자체에 중점을 두겠습니다. 일상적으로 직접 사용하게 될 API는 아닙니다.

최근 렌더러 기능을 개발하신다면, 대부분 Render Graph를 사용하실 것입니다. 따라서 이곳의 일부 세부 사항은 RHI 내부의 매우 낮은 수준에 관한 것이지만, 이를 아는 것은 여전히 매우 유용합니다.

성능 분석 시 병목 지점이나 스레딩 현황 등을 파악하고자 할 때 유용합니다.

코드에서 사용될 몇 가지 상위 레벨 타입을 정의하겠습니다. `frhi-commandlist`-based 타입은 RHI commandlist 기록을 위한 대부분의 구현을 포함합니다. 또한 이를 상속받는 세 가지 파생 타입이 있으며, 이들은 draw call API, dispatch API 등에 접근할 수 있게 해주는 adaptor 클래스입니다. 특별한 경우로 `RHI command list immediate`가 있습니다. 이 immediate command list는 엔진 내의 singleton이며, render thread가 소유하고 GPU에 작업을 제출하기 위한 파이프라인의 주요 진입점 역할을 합니다.
각 플랫폼 RHI별로 구현되는 타입도 있습니다. 각각의 RHI 모듈에서 구현되는 base interface들이 존재합니다. 주요 타입으로는 `RHI compute context`와 `RHI command context`가 있습니다. RHI의 context는 객체들을 나타냅니다.

렌더러에서 기록된 RHI commands를 실제 GPU 하드웨어에서 실행되는 GPU commands로 변환하는 과정에 관여합니다. 따라서 D3D12를 호출하여 D3D command lists를 생성하는 맥락에서 이야기하고 있습니다. 이렇게 생성된 D3D command lists는 IRHI platform command list 타입으로 래핑되어 관리 및 submission pipeline에 사용됩니다.

이 시스템은 UE4 초기, 혹은 UE3 시절부터 존재해왔기에 관련된 많은 legacy name들이 존재함을 인지하시는 것이 좋습니다. IRHI command context는 그래픽스 pipe에 특화되어 있지만, 해당 용어는 포함하고 있지 않습니다.

IRHI compute context가 존재함에도 불구하고, 컴퓨트 그래픽스(compute graphics) 관련 용어가 아직 변경되지 않았습니다. 언젠가는 이러한 명칭들이 수정될 것이라 확신합니다.

렌더러와 렌더 그래프는 FRHI command list의 인스턴스를 생성합니다. 각 recording thread마다 하나씩 존재하며, 이 command list에 삽입되는 명령어들은 CPU 순서대로 처리됩니다. 단, 하나의 RHI command list는 여러 RHI context에 작업을 기록할 수 있습니다. 각 pipeline(graphics 또는 compute)마다 하나의 context가 할당되며, 일반적으로 command list당 하나 또는 두 개의 context가 사용됩니다.
명령어가 삽입될 때, switchPipeline과 enqueue lambdaMultipipe 함수를 사용하여 적절한 context로 명령어의 방향을 전환합니다. 예를 들어, RenderGraph가 그래픽 큐와 컴퓨트 큐를 위한 패스를 각각 다시 실행할 때, RenderGraph 내부에서는 switchPipeline 호출을 통해 ASINCompute로 전환하게 됩니다.
모든 RHI command list는 immediate command list를 통해 submit되며, queue async command list submit 및 immediate flush 함수를 사용합니다. 모든 command list는 두 단계로 작동합니다. 초기 기록 단계와 이후에 "translation"이라고 불리는 단계입니다. translation은 다시 실행하는 과정을 의미합니다.

기록된 명령어들을 RHI context로 호출하여 실제 GP platform commands를 생성하는 과정입니다.
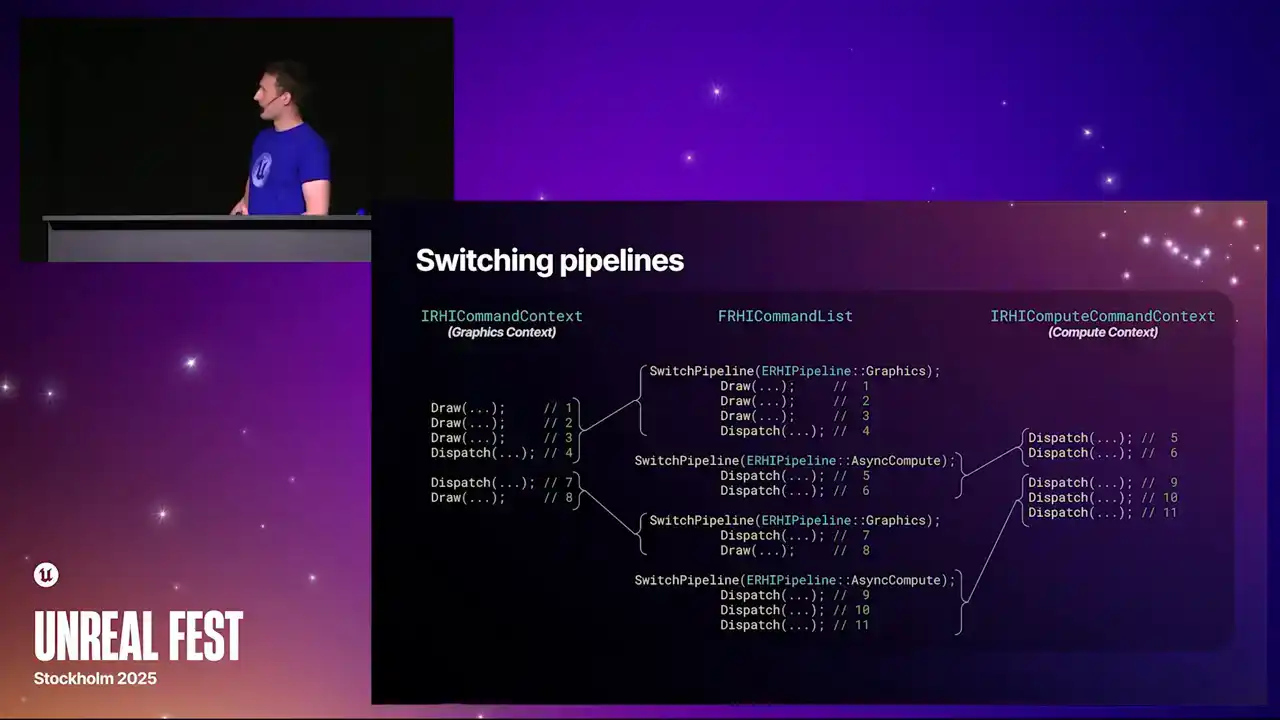
이것이 바로 스위치 파이프라인의 모습입니다. 중앙에는 많은 명령이 포함된 명령어 리스트 예시가 있습니다. 그리고 명령어 리스트를 통해 번역 시, 해당 명령들을 적절한 컨텍스트로 전달하는 스위치 파이프라인 호출이 인터리빙됩니다. 또 하나의 주목할 점은 컨텍스트 자체가 지연 로드(lazily)된다는 것입니다. 따라서 명령어 리스트가 그래픽스만 사용하는 경우, 그래픽스 컨텍스트만을 획득하고 그래픽스 파이프라인 작업만 수행하게 됩니다. 이는 기존의 번거로움을 줄여줍니다.

두 가지를 동시에 진행하려 하면, 아무런 작업 내용도 포함되지 않은 context가 생성되어 불필요한 overhead만 발생합니다. 따라서 이 지점에서 사과드립니다. 발표 노트에서 직접 읽는 방식으로 전환하겠습니다. 이 슬라이드는 매우 복잡하며, 정확한 전달을 위해 많은 정보를 숙지해야 하기 때문입니다.
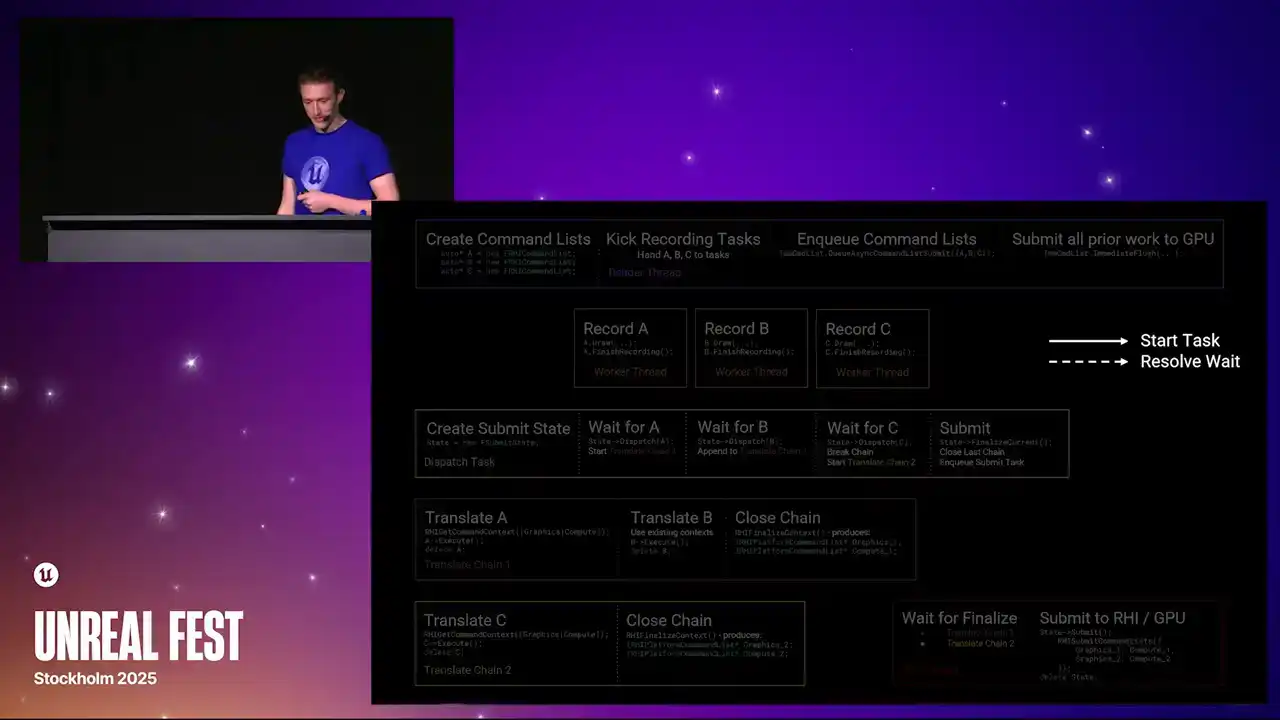
이에 따라 제 노트만 보시고 따라오시면 됩니다. 앞으로 몇 장의 슬라이드를 통해 RHI command list가 생성되고, 기록되며, 디스패치, 번역, 그리고 GPU에 제출되는 과정을 예시와 함께 설명해 드리겠습니다. 이는 다단계 과정으로, 많은 작업과 병렬 처리가 수반됩니다. 슬라이드에 담긴 모든 정보를 즉시 파악하실 필요는 없으며, 각 단계를 차례대로 설명해 드릴 것입니다.

작업 흐름을 보여주기 위해 슬라이드에 화살표를 추가합니다. 실선 화살표는 한 작업이 다른 작업을 시작하는 위치를 나타내고, 점선 화살표는 대기가 해소되는 위치를 나타냅니다. 색상 상자는 스레드 또는 작업 체인을 나타냅니다. 이들은 슬라이드에서 왼쪽에서 오른쪽으로 실행됩니다.
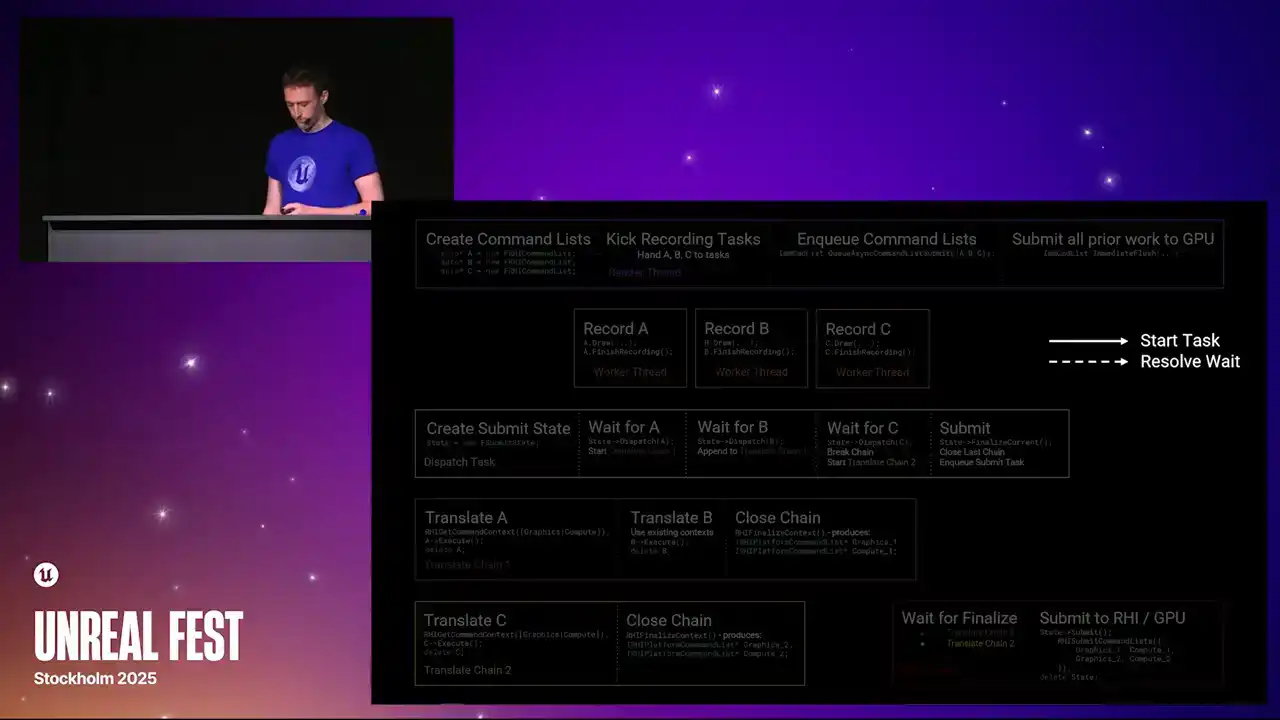
렌더링 스레드는 세 개의 RHI command list(A, B, C)를 생성하고, 병렬로 작업을 기록(record)합니다. RenderGraph Parallel Pass Execution이 주요 태스크 소스이며, 모든 작업 기록이 완료되면 `Finish Recording`을 호출하여 command list가 준비되었음을 알립니다.
이후 렌더링 스레드는 `QAsync Command List Submit`을 호출하여 A, B, C 순서로 command list를 GPU에 제출합니다. `QAsync command list submit`은 `dispatch task`를 실행하여 command list들을 `translate chain`으로 묶어 병렬 처리를 수행합니다.
`dispatch task`는 첫 번째 command list(A)의 완료를 기다린 후, 새로운 `translate chain`을 시작합니다. `translate chain`은 기록된 명령어를 RHI context에 재연결(replay)하며, GPU별 command list를 생성합니다. A의 번역이 진행되는 동안 B의 기록이 완료되면, `dispatch task`는 B를 첫 번째 `translate chain`에 추가합니다.
A와 B의 번역 및 실행 후 삭제가 끝나면, `dispatch task`는 C를 첫 번째 체인에 추가하지 않고 병렬성을 높이기 위해 체인 1에 `close command`를 발행합니다. 이는 RHI context를 최종화하여 GPU 제출 준비가 된 플랫폼별 command list 포인터를 생성합니다.
동시에 두 번째 `translate chain`이 시작되고 C가 처리됩니다. 렌더링 스레드는 `immediate flush`를 호출하여 모든 작업 제출을 GPU에 보냅니다. `immediate flush`는 마지막 `translate chain`을 닫고, RHI 스레드는 이를 받아 플랫폼 RHI 구현으로 전달하여 GPU에 제출합니다. 체인 1의 작업이 체인 2보다 먼저 제출되며, 최종적으로 상태 추적 구조체가 삭제됩니다.
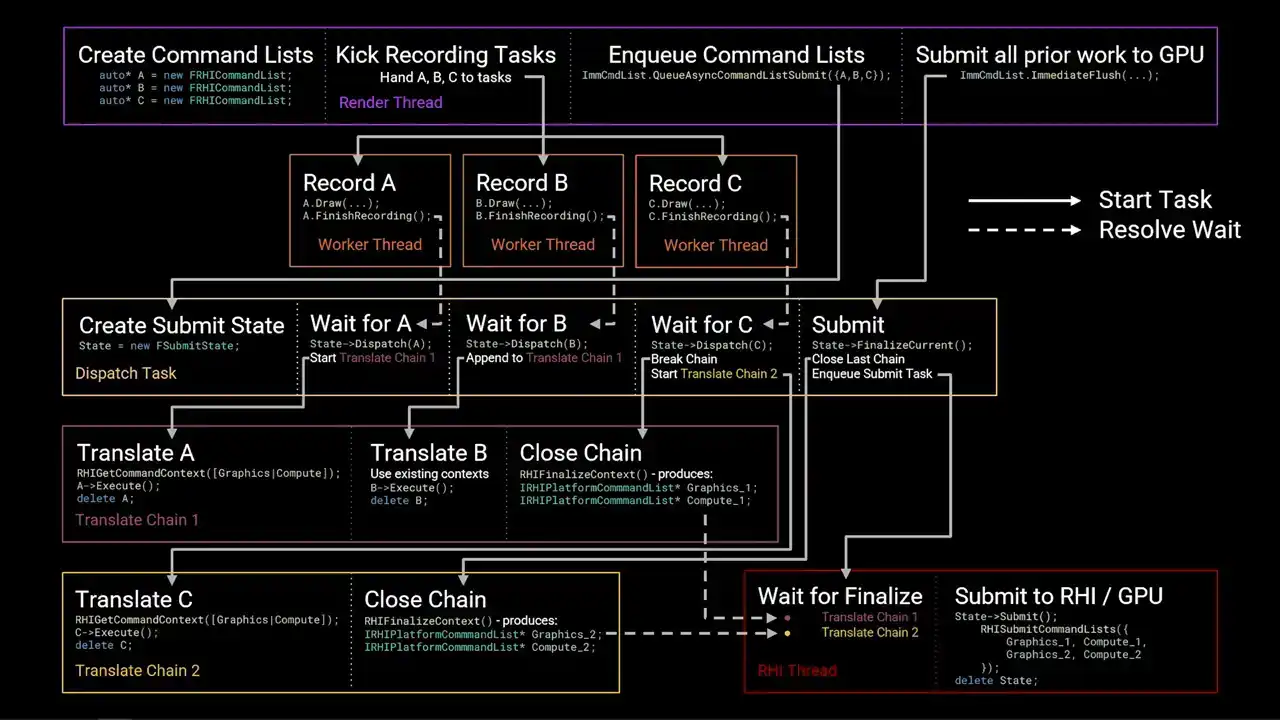
RHI thread까지 전부.
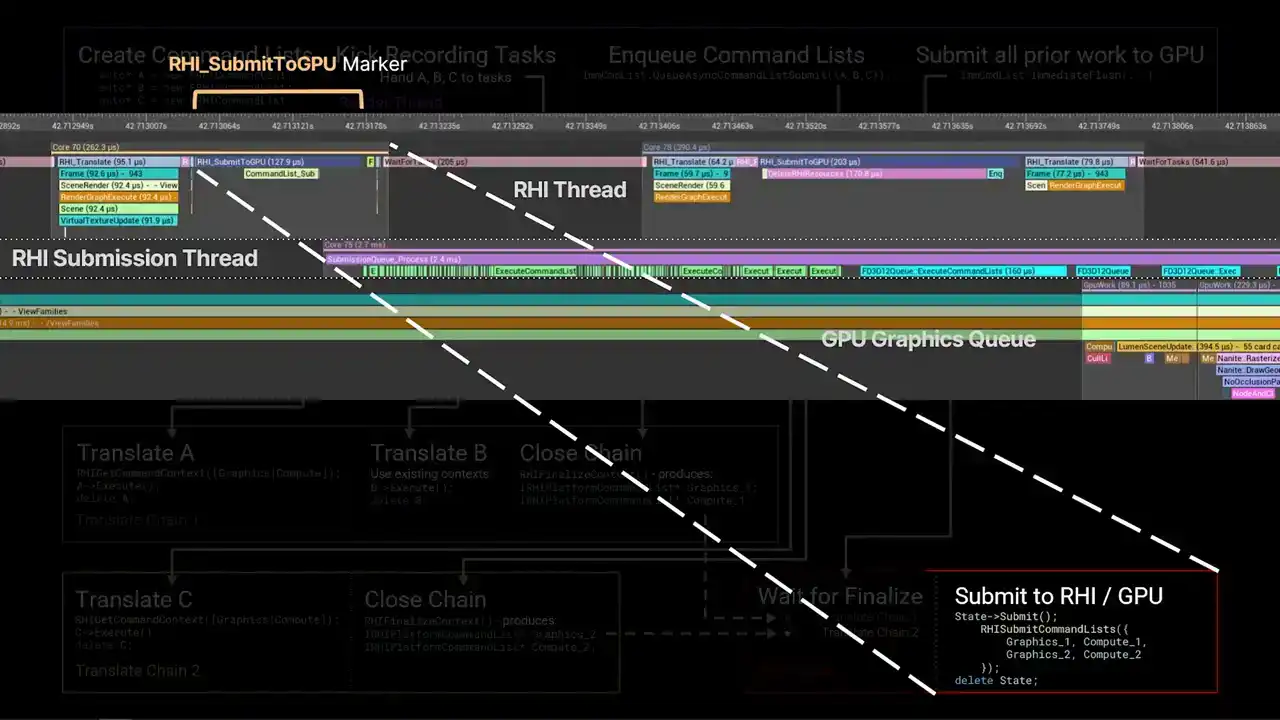
흥미로운 점은, 이 최종 우측 하단의 박스가 앞에서 Unreal Insights를 언급할 때 말씀드렸던 마커라는 것입니다. RHI 스레드에서 발생하는 RHI submit to GP 마커입니다. 따라서 전체 flow graph는 해당 시점까지 이어집니다. 그 이후에는 platform command lists가 platform RHI로 푸시(push)됩니다.
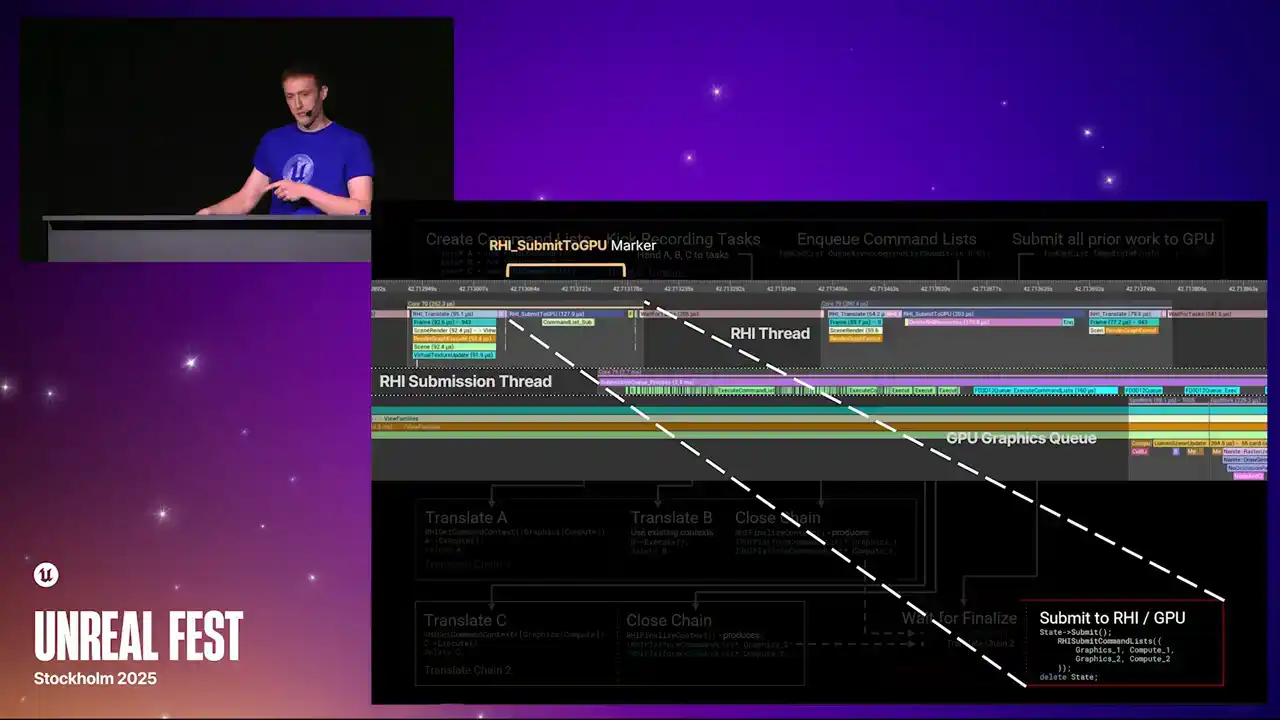
GPU의 작동 방식은 현재 사용하시는 플랫폼의 구체적인 구현 세부 사항에 해당합니다.
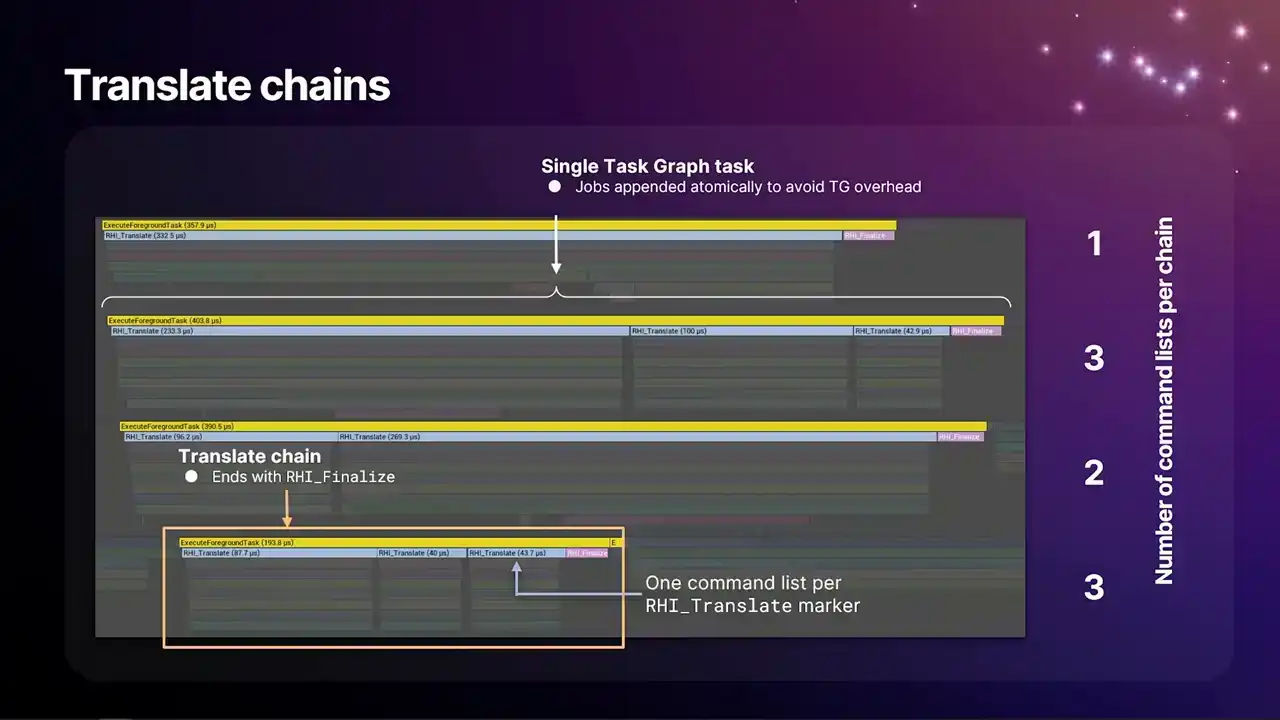
여기 보이는 것이 Insights Capture 시 얻을 수 있는 translate chains의 모습입니다. 각 줄은 하나의 translate chain을 나타냅니다. 줄 안의 파란색 마커들은 translate되는 RHI command list 하나하나를 의미합니다. 각 translate chain 위에는 `RHI_translate` 마커가 있습니다. 또한 각 chain은 끝에서 핑크색 마커인 `RHI_finalized_command`로 마무리됩니다. 저희는 task graph overhead를 줄이기 위해, 이러한 chains를 빌드하는 과정에서 특정 기법을 사용합니다.
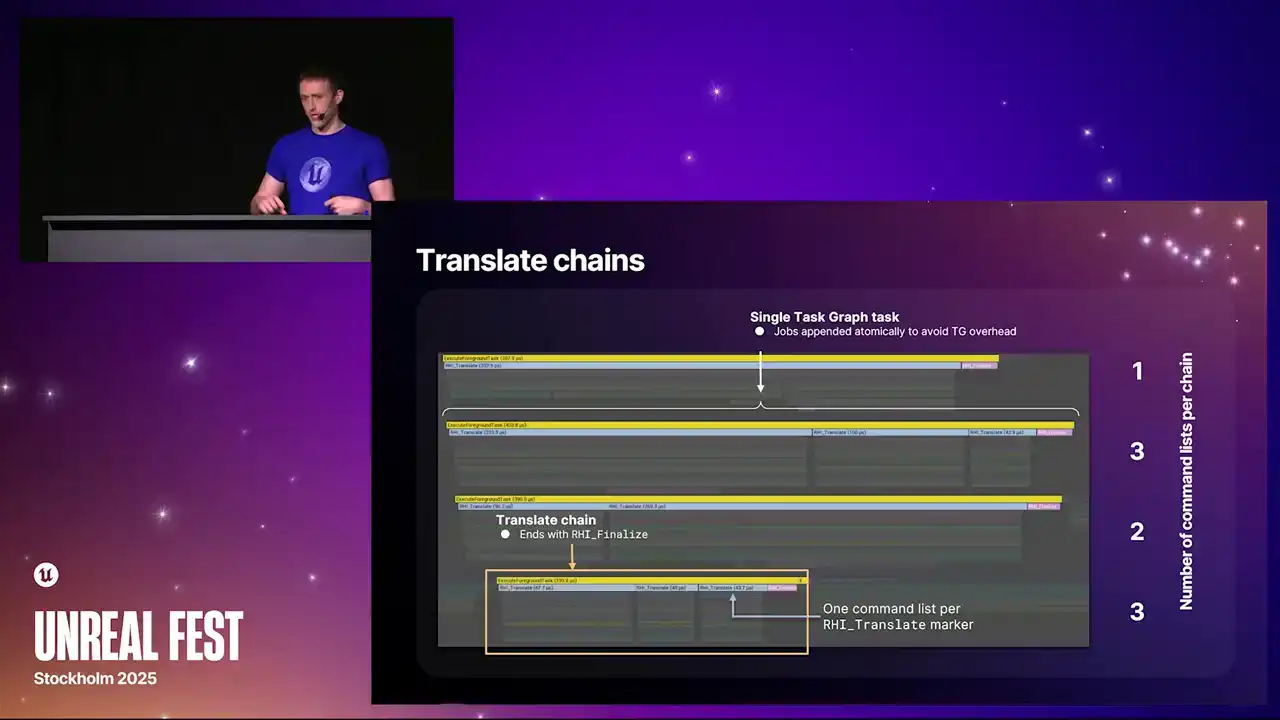
기존 명령 리스트 체인의 끝에 command lists를 atomically하게 추가합니다. 이 방식은 task가 command list가 도착하기 전에 완료되었다면, 이어질 다른 command list가 있음을 인지하고 이를 pop하여 다시 loop를 돌며 실행하게 합니다.

각 커맨드 리스트가 Task Graph Task였던 이전 버전에서는 각 요소 사이에 간격이 존재하여 오버헤드가 과도했습니다. 이를 최소화하기 위해 수정되었습니다. 여기서 핵심은 언제 정확하게 체인을 끊을 것인가 하는 문제입니다.
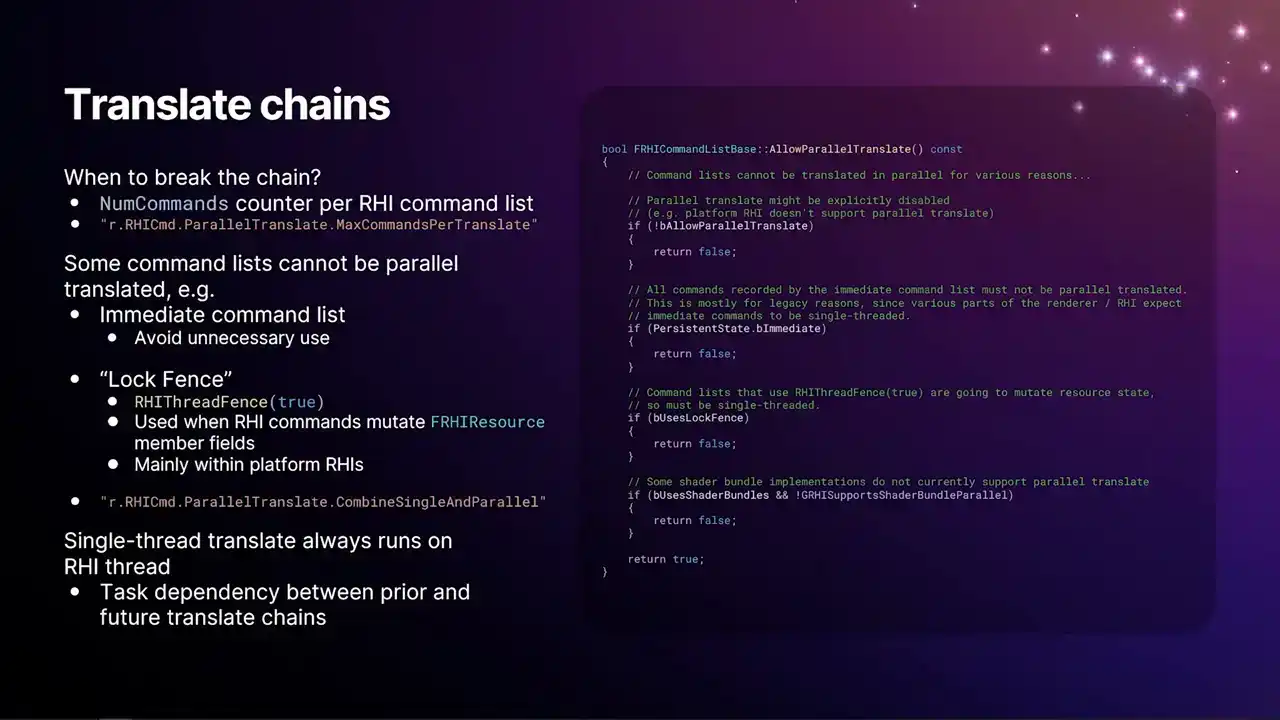
RHI command list에 있는 command 수를 기준으로 병렬 처리 범위를 결정합니다. 각 RHI command list에는 num commands 필드가 있으며, command 할당 시 해당 카운터가 증가합니다. 이 정보를 통해 dispatch thread 또는 task에 도달했을 때 command list의 크기를 파악할 수 있습니다.
CVAR `r.rhiCommand.parallelTranslate.maxCommandsPerTranslate`는 병렬 처리될 command 수의 상한선(high watermark)을 설정합니다. 이 값을 천(1000)으로 설정하면, 다음 command list가 이 제한에 도달할 때까지 chain을 빌드하고 새로운 chain을 시작합니다.
하지만 이 메커니즘 외에도 특정 command list에서 병렬 처리를 수행할 수 없는 몇 가지 이유가 있습니다. 상세한 이유는 코드 스니펫을 참조하십시오.

이것은 바로 Global Singleton인 Immediate Command List를 사용하는 경우입니다. 이는 Render Thread가 소유하고 있으며, UE4 초기부터 존재해 왔습니다. 해당 Command List에 의존하던 많은 시스템들이 thread-safe하지 않아 병렬 처리가 불가능했습니다. 따라서 오늘날에도 Immediate Command List를 사용하는 모든 경우에 해당됩니다.

드로잉 작업은 단일 스레드로 처리되어 성능 저하를 유발할 수 있습니다. 따라서 불필요한 사용은 피하는 것이 좋습니다. 이는 렌더 그래프 패스에서 커맨드 리스트 타입을 지정할 때 유의해야 함을 의미합니다.

`Command List`에서 `Base`를 사용하시면 병렬 처리가 가능합니다. 하지만 `Immediate Command List`를 사용하시면 문제가 발생할 수 있습니다. `Lock Fence`라는 메커니즘도 존재합니다.
이 기능의 이름은 GPU 버퍼 업데이트를 위한 RHI buffers의 lock 및 unlock에서 유래했습니다. 현재는 CPU 측에서 RHI resource를 변경하는 모든 RHI command에 사용됩니다.
버퍼가 이 기능을 사용하는 이유는 대부분의 플랫폼에서 lock 및 unlock 시 원본 버퍼를 직접 수정하는 것이 아니라, stall을 피하기 위해 GPU 메모리에 완전히 새로운 버퍼를 할당하기 때문입니다.
이후 일종의 swap이 이루어지며, 이를 'rename'이라고 부릅니다. RHI에 현재 버퍼를 가리키는 포인터가 있고, 이 값이 이전 값으로 swap 되면 이전 버퍼는 discard 및 free됩니다.
하지만 여러 translate가 병렬로 발생할 경우, lock 이전의 모든 command는 이전 값을 보고 lock 이후의 command는 새로운 값을 보도록 보장해야 합니다. 이를 위해 단일 스레드 translate로 fallback하게 됩니다.

이것이 RHI thread fence에 `true`를 인자로 전달했을 때 발생하는 현상입니다. 하지만 이는 API의 구현 세부 사항일 뿐, 직접적으로 문제가 발생하지는 않을 수 있습니다.
특정 API는 이러한 mutate를 내장하고 있습니다. 마지막으로, `r.rhicommand.parallelTranslate.combine single and parallel`이라는 추가 콘솔 변수가 있습니다. 이 변수가 활성화되면, 병렬 번역이 가능했던 모든 RHI command list는 단일 스레드로 강제 전환되는 번역 체인에 포함될 후보가 됩니다. 이 설정을 끄면,

RHI command list는 병렬로 번역될 수 있는 경우 모두 병렬로 번역됩니다. 또한, 단일 스레드로 번역되어야 하는 다른 command list 때문에 RHI thread에만 국한되어 실행되지 않습니다. 따라서 이 console variable과 max commands to translate one은 renderer의 폭을 결정하는 두 가지 주요 튜너블입니다.

질문하신 두 가지 사항은 실험 및 성능 측정(perf captures)을 진행하고자 하는 대상입니다. 하드웨어의 코어 수가 적거나 많음에 따라, 일반적으로 멀티코어 시스템에서는 더 넓게(wider), 제한적인 시스템에서는 더 좁게(narrower) 최적화하는 것이 좋습니다.
또한, 언급했다시피 single thread translate는 항상 RHI thread에서 실행됩니다. 이는 특정 코드들이 물리적인 RHI thread 상에서 실행되는 것을 가정하기 때문인 레거시(legacy)적인 이유 때문입니다.

이것은 일부 task dependencies를 사용하여 달성되었습니다.
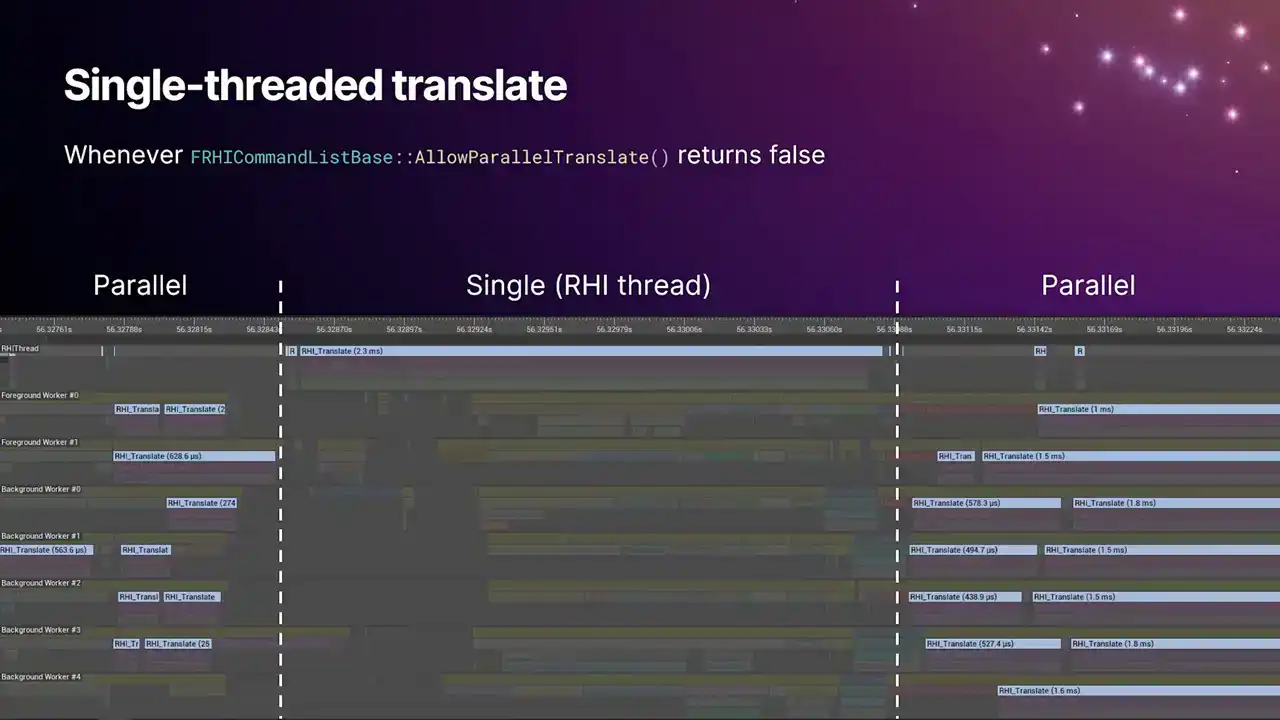
Insights에서 이와 같이 나타납니다. Paradox Translate function이 command list에서 false를 반환할 때마다 single thread translate이 발생합니다. 병렬 작업 두 블록 후 잠시 single thread로 fallback되는 것을 볼 수 있습니다. 이 스크린샷은 약 1년 전의 것으로, ray tracing API가 immediate command list를 사용했던 것이 특정 single thread translate의 원인이었습니다. 현재는 수정된 것으로 생각됩니다. 우리는 pipeline의 병목 현상인 single thread translate의 양을 줄이기 위해 노력하며 점진적으로 발전하고 있습니다.

이것은 확장성이 좋지 않습니다.

앞서 말씀드린 내용에 대한 몇 가지 주의사항과 명확화를 덧붙입니다. 어떤 스레드든 RHI command list instance를 생성할 수 있지만, 이를 제출하는 것은 render thread만 가능합니다. Mesh streaming system이 좋은 예시입니다. Mesh를 스트리밍하기 위해서는 vertex 및 index 데이터를 하드 디스크에서 가져와야 합니다. PC 환경에서 이 데이터를 실제 GPU 메모리로 옮기는 작업은 GPU에서 이루어집니다. Windows와 같은 OS는 데이터를 시스템 메모리, 즉 upload heap까지 가져오는 것을 도와줍니다. 그 후 GPU는 실제로 해당 데이터를 자체 로컬 메모리로 복사해야 합니다. 따라서 RHI에 버퍼를 생성하려면 command list가 필요합니다. 버퍼를 생성하는 함수는 command list 타입에 있습니다. MeshStreamer에서는 백그라운드에서 실행되는 MeshStreamer thread가 자체 RHI command list를 생성합니다. 이를 사용하여 버퍼를 생성하고 초기 데이터로 채웁니다. 그리고 MeshStreaming 시스템의 마지막 단계인 버퍼가 renderer에게 전달될 때,

렌더 스레드에서 작업이 enqueued됩니다. 이후 생성된 command list가 함께 전달되어 immediate command list를 통해 submit됩니다. 이 시점부터 buffers는 안전하게 사용할 수 있습니다. 이처럼 handover mechanism이 작동합니다.

Dispatch task는 단일 submit에 국한되지 않습니다. 이는 일종의 thread와 같다고 생각하시면 됩니다. 물리적인 thread는 아니기에 그렇게 부르지는 않지만, 의존적인 task들이 연속적으로 이어지는 chain이라고 볼 수 있습니다. 앞에서 설명했던 flow graph 예시에서는 dispatch task가 특정 submit에만 관련 있는 것처럼 보일 수 있지만, 실제로는 양쪽 끝에서 다른 task들과의 dependencies를 가지고 있습니다.

이것은 일련의 작업(chain of tasks)일 뿐입니다. 따라서 이전 작업들이 제출 순서(submission order)대로 완료되지 않으면 다음 작업에 대한 dispatch가 실행되지 않습니다. 하지만 일반적으로 dispatch 작업들은 매우 짧기 때문에 병목(bottleneck)으로 작용하는 것을 보기 어렵습니다. recording 및 translate chain 작업들의

`translate` job들이 task graph에서 순서에 상관없이 실행되므로 완료 순서가 뒤죽박죽될 수 있습니다. 이 때문에 `lock fence` 등을 사용하여 작업 완료 후 재정렬하는 로직이 필요합니다.
이렇게 재정렬된 작업들은 GPQ(Graphics Processing Queue)에 순서대로 입력됩니다. `immediate command list` 역시 `parallel command list`와 동일하게 드로잉 등 모든 작업을 수행할 수 있습니다.
하지만 `immediate command list` 사용은 권장되지 않으며, 특별한 이유가 없다면 `parallel command list` 사용을 지양해야 합니다.

`Finish recording`은 이러한 병렬 작업을 가능하게 하기 위한 메커니즘이었으며, 즉각적인 명령 목록에서 수행할 필요는 없습니다. 오히려 그렇게 하면 충돌이 발생할 수 있습니다. 해당 부분에 `assert`가 있을 것으로 예상됩니다.

여기까지가 저희의 Submission Pipeline 관련 내용이며, 이제 RHI Breadcrumb System에 대해 말씀드리겠습니다.

RHI breadcrumb system은 새로운 GP profiler에서 구현된 모든 것의 기반을 형성합니다.

엔진과 렌더러에는 렌더러 작업을 분류하여 PixCapture 등에서 작업 내용을 확인할 수 있도록 하는 여러 시스템이 있었습니다. 이러한 시스템들은 서로 경쟁했으며, 모든 스레딩 시나리오에서 정확하지 않았습니다. 또한 엔진은 다양한 플랫폼에서 여러 방식으로 스레드를 실행합니다. 따라서 모든 것을 통합할 시스템이 필요했으며, 그 결과 Archive Broke-Rub 시스템이 탄생했습니다. Insights에서 이를 확인할 수 있습니다. 슬라이드에서는 잘 보이지 않을 수 있습니다.
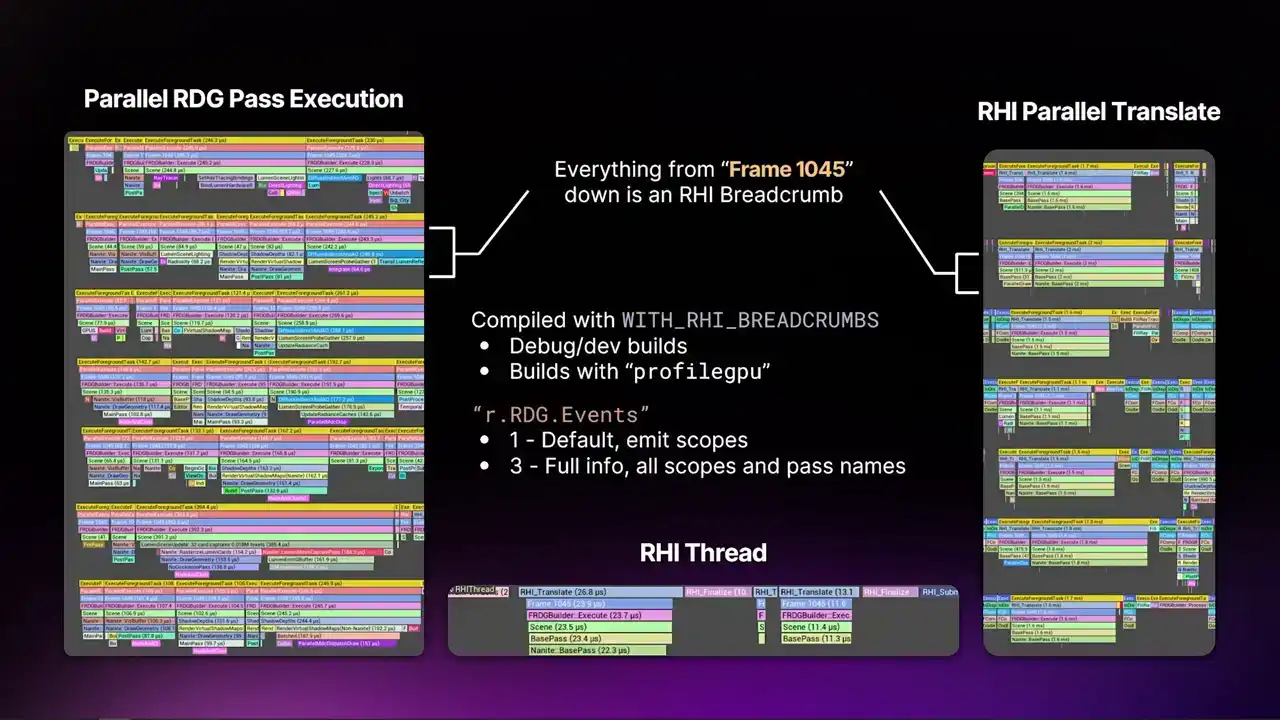
프레임 마커부터 아래 영역에 표시된 부분은 모두 breadcrumb입니다. breadcrumb은 렌더러의 특정 영역에 고유한 이름을 태그한 것입니다. 이 동일한 breadcrumb은 가능한 모든 곳에 나타납니다. render thread, parallel pass RDG execution, parallel translate, RHI thread 등에서 이를 확인할 수 있습니다. GPU에서도 동일하게 나타나며, 이는 처음부터 끝까지 모두 같은 마커를 사용하고 있음을 의미합니다.

이는 스레드가 무엇을 작업하고 있는지에 대한 실제적인 컨텍스트를 제공합니다. 이전에는 단순히 "render graph stuff"를 수행한다는 것만 알 수 있었고, 구체적으로 어떤 pass를 작업하는지는 알 수 없었습니다. 만약 어떤 작업이 매우 비싸다면, sampling 등의 프로파일링이 필요했습니다. 이제 이 정보는 해당 macro가 활성화된 모든 빌드에서 제공됩니다.

RHI breadcrumbs 기능은 기본 UE의 모든 debug 및 dev config build에서 제공되며, profileGPU 명령이 활성화되었을 때도 사용할 수 있습니다. 또한, test 또는 shipping 빌드에서도 추가 매크로를 통해 이 기능을 활성화할 수 있습니다.
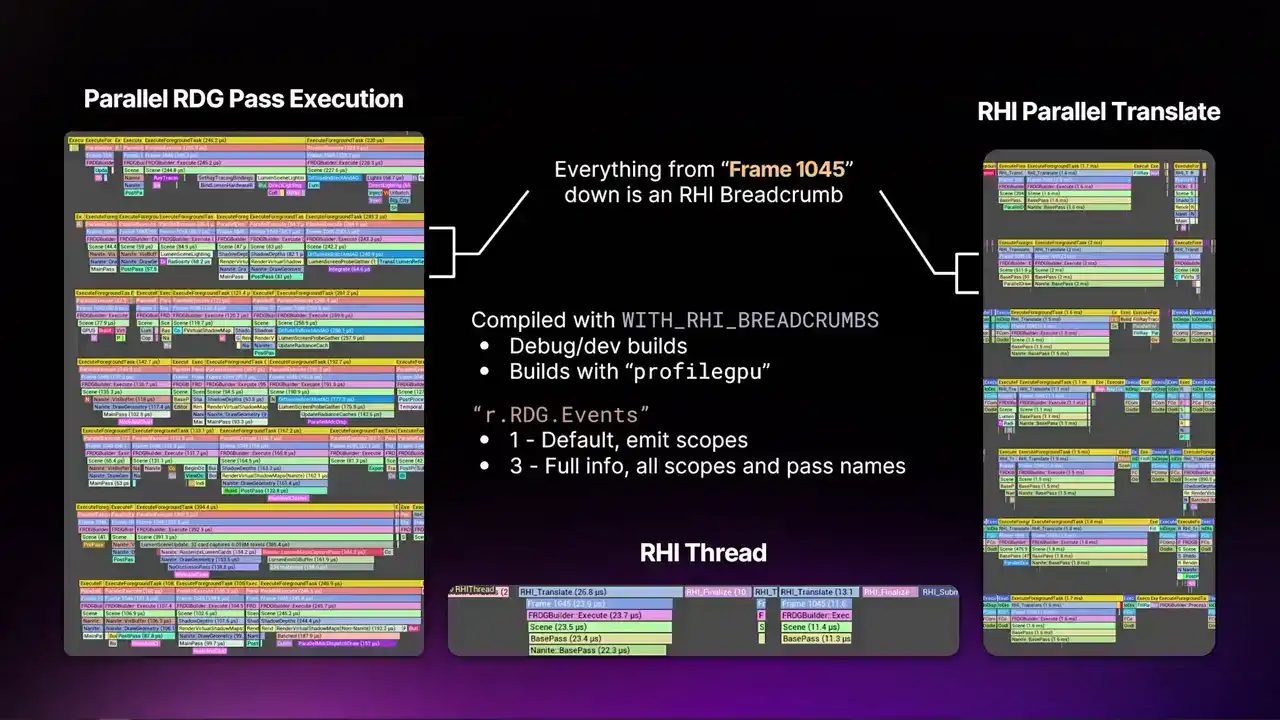
이 작업을 수행하시면, breadcrumb system 또한 함께 얻게 됩니다. profileGPU가 정상적으로 작동하기 위해 breadcrumb system에 의존하기 때문입니다. 또한, r.rdg.events라는 콘솔 변수도 있습니다. 이 변수는 render graph가 얼마나 많은 디테일을 처리할지 결정합니다.

Breadcrumb system으로 emit 합니다. 당연히, 모든 detail을 항상 emit하는 것은 emit하지 않는 것보다 비용이 더 많이 듭니다. 따라서 기본값으로는 scene, base pass와 같은 high-level scope만 emit하게 됩니다.

post-processing 등 관련된 정보는 레벨 3까지 최대로 설정할 수 있습니다. 레벨 3에서는 모든 scope, 모든 info, 모든 pass name과 그 parameter까지 확인할 수 있습니다. 이것이 사실상 암묵적으로 적용되는 내용입니다.

'profile GPU'를 실행하면 내부적으로 Cvar 값이 3으로 설정되어 'profile GPU capture' 시 모든 정보를 얻을 수 있습니다.

코드상에서 실제 모습은 이러합니다. 여러 시스템이 통합되면서 다양한 scope macros가 같은 시스템으로 연결됩니다. macro들의 구현은 모두 동일한 지점으로 수렴합니다. renderer 주변에는 기존의 scope drawer events가 있으며, 좌하단에는 새로 추가된 Breadcrumb macro가 있습니다. 이 macro는 RHI command list 또는 RHI context를 받아들일 수 있어, platform RHI 내부에서도 활용됩니다.
슬라이드의 D3D12 defrag pass 예시처럼, platform RHI에 특화된 사항도 동일한 Breadcrumb 시스템으로 레이블링할 수 있습니다. 이렇게 하면 Insights, PICs 등 어디서든 해당 마커들을 확인할 수 있습니다. 우측의 render graph에서는 기본적으로 event scopes가 제공되며(events >= 1), 하단에는 pass names가 있습니다.

시스템을 완전히 켰을 때 보게 되는 것들입니다.

이것은 breadcrumb 시스템의 작동 방식에 대한 간략한 개요입니다. RHI command lists를 기록할 때, 실제 breadcrumb 이름을 참조하는 RHI breadcrumb node들의 tree를 구축합니다. 이 모든 코드는 cross-platform이므로 모든 플랫폼에서 작동합니다. Mesh streamer와 같이 RHI command lists는 render thread와 별개인 완전히 분리된 thread에서 기록될 수 있습니다. 각 RHI command list 자체는 scope를 드나들면서 node들의 subtree를 구축합니다.
dispatch 시점에 dispatch thread가 해당 command list를 submission을 위해 획득하면, root tree에 attached됩니다. 그러면 이러한 subtree들은 전체 frame에 대한 overarching tree에 나타나며, frame marker까지의 전체 context를 얻게 됩니다. 또한 format args를 by-value capture합니다. 이러한 방식의 주된 이유는 모든 context를 capture할 수 있도록 하기 위함입니다. 예를 들어, frame의 시작 부분에 marker가 있습니다.

이는 정수 n을 나타내는 frame입니다. 단순히 frame이라 부르지 않고 추가적인 컨텍스트를 제공하기 위해, 정수에 해당하는 4바이트와 format string에 대한 포인터를 캡처합니다. 이로써 실제 이름이 필요할 때만 formatting을 수행하면 됩니다.

Insights를 직접 실행하거나 Profile GPU의 특정 프레임을 스냅샷으로 캡처하지 않는 경우, 문자열 포맷팅을 수행하지 않아 훨씬 효율적입니다. Archive Command List에는 직접 호출할 필요는 없지만, 명확성을 위해 몇 가지 함수를 소개합니다. Begin/End Breadcrumb CPU 및 Begin/End Breadcrumb GPU 함수가 그것입니다. CPU 함수는 Insights 마커를 삽입하는 데 사용되며, 이를 통해 Insights로 데이터를 전송합니다. 또한 CPU 크래시 리포팅에도 활용됩니다. 엔진 이전 버전에서는 렌더 그래프 패스 내에서 스레드가 충돌하면 일반적인 콜 스택만 표시되었지만, 이제는 이 기능이 매우 유용합니다.

호출 스택만으로는 실행된 task가 task graph에서 왔다는 것 외에 더 많은 정보를 얻을 수 없습니다. 어떤 pass였는지, 혹은 그와 관련된 어떤 정보도 알 수 없습니다. 특히 Compute Shader Pass의 경우 문제가 됩니다. Compute Shader Pass는 `add Compute Shader Pass`라는 일반적인 함수가 있으며, 호출 스택으로는 어떠한 context도 얻을 수 없습니다.
이제 충돌 발생 시, 충돌 스레드의 breadcrumbs stack을 crash report에 덤프할 수 있게 되어 추가적인 정보를 모두 얻을 수 있습니다. 마찬가지로 parallel translator의 경우, RHI 내에서 충돌이 발생하더라도 프레임의 어느 부분에서 왔는지 알 수 있습니다.

CPU 기능은 트리를 구축하는 역할을 수행합니다. 이 기능들은 모든 bookkeeping 및 관련 작업들을 처리합니다. 엔진 내 다양한 threading mode가 존재하므로, 이 부분을 완벽히 이해하는 데는 다소 복잡할 수 있습니다. 개발 과정에도 시간이 소요되었습니다. 모든 bookkeeping 작업은 이곳에서 이루어집니다. 이후 GPU 기능이 실제로...

현재 보이는 pix markers, render.markers, 그리고 insights GPU markers를 삽입하고 렌더링하십시오. 이를 통해 GPU crash debugging을 위한 새로운 시스템도 얻게 됩니다.
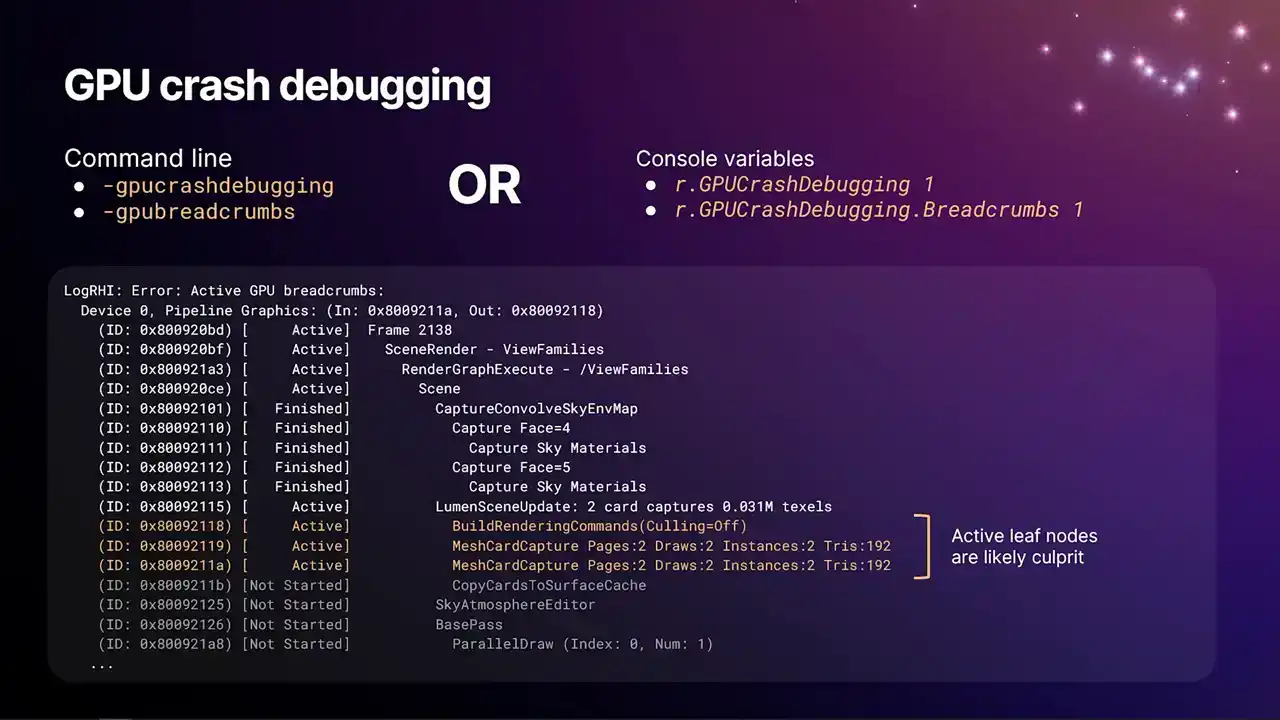
새로운 GPU crash debugging 시스템은 위 옵션들을 통해 활성화할 수 있습니다. 커맨드 라인에서 `-dash GPU crash debugging`, `-dash GPU breadcrumbs` 또는 해당 CVAR (r.gp_crash_debugging 1, r.gpcraftabugging.breadcrumbs 1)을 사용하시면 됩니다. 상단 옵션은 여러 시스템을 활성화하는 반면, 하단 옵션은 슬라이드에 표시된 특정 시스템만 활성화합니다.
이 시스템은 RHI context에서 breadcrumbs를 replay하며 GPU command list를 생성할 때 작동합니다. D3D12의 경우, breadcrumb scope에 진입하고 나갈 때마다 write buffer immediate를 사용하여 command list stream에 정수를 직접 기록합니다. 이 정수들은 영구적으로 유지되는 버퍼에 기록됩니다.

GPU가 크래시되더라도 Windows의 메커니즘을 통해 데이터를 복구할 수 있습니다. GPU는 프레임 진행 상황을 지속적으로 마킹하며, RTI interrupt thread에서 GPU 크래시 및 device removed error를 감지하면 crash handler로 진입하여 해당 정수 값을 가져옵니다. 이를 통해 아직 완료되지 않은 GPU 작업 목록에서 해당 마커 범위를 찾아 로그로 덤프할 수 있습니다. 멀티 GPU, 멀티 큐 환경을 지원하므로 각 큐별로 덤프가 생성됩니다.
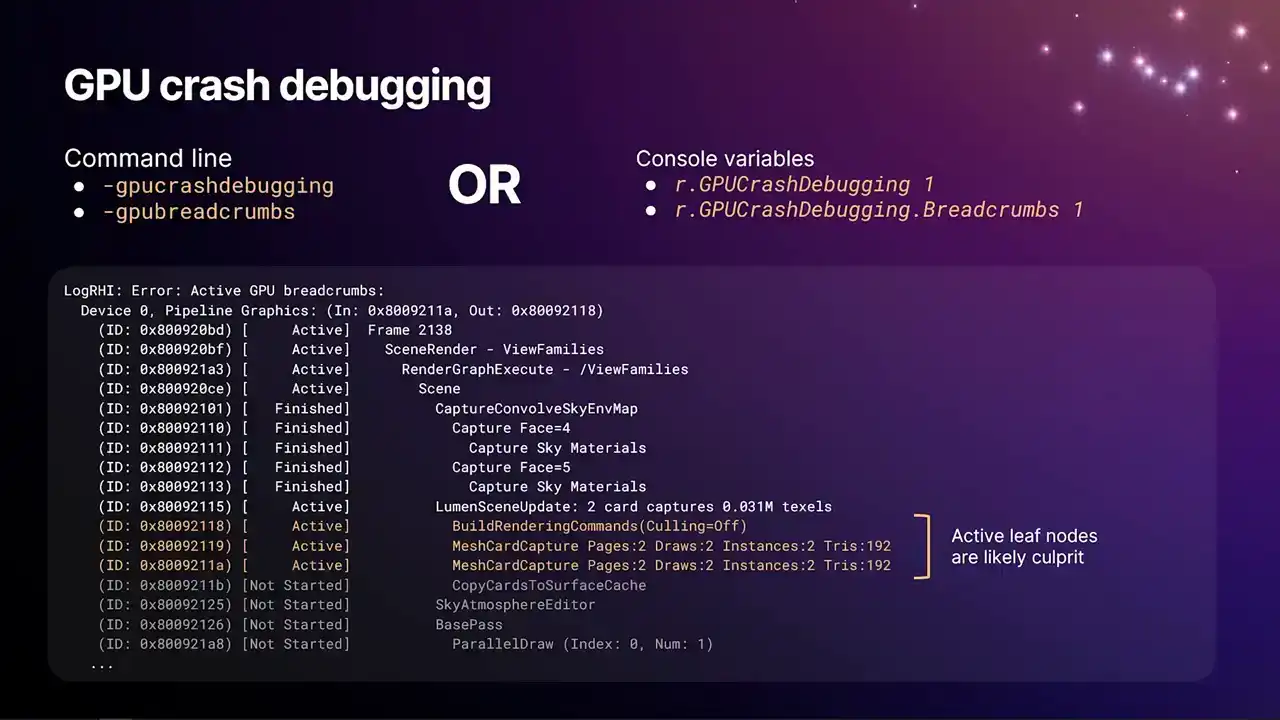
이 예시는 매우 유용합니다. 슬라이드를 준비하던 중, 누군가 Lumen에서 GPU crash가 발생했습니다. 해당 로그를 가져와 여기에 바로 dump할 수 있었습니다. GPU hang 테스트 명령이 존재하지만, 이는 다소 인위적인 예시입니다. 과거에는 GPU crash 및 hang 발생 시, 로그를 통해 원인을 파악했습니다.
이 경우 Lumen 관련 부분이 crash의 원인이었습니다. 가장 많이 indent되고 여전히 active로 표시된 노드들이 유력한 용의자이며, 이는 주황색으로 강조 표시됩니다. 회색으로 표시된 부분은 GPU가 아직 해당 작업을 시작하지 않았음을 나타냅니다. 따라서 이 부분은 culprit가 아닙니다.

하드웨어는 작업이 실제로 완료되지 않았음에도 완료를 보고할 수 있다는 점에 유의해야 합니다. GPU에서 여전히 페이지 폴트를 유발할 수 있는 메모리 연산이 진행 중일 수 있습니다. 따라서 완료로 표시된 일부 노드는 주의해서 받아들이고, 여러 번 재현하여 상한값이 크게 변동하는 패턴이 있는지 확인하는 것이 좋습니다. 이로써 거의 모든 내용을 다루었습니다.

이곳의 모든 정보가 여러분의 게임 프로파일링과 끔찍한 CPU 및 GPU 병목 현상 해결에 도움이 되기를 바랍니다.

정말 감사합니다. 이제 질의응답 시간을 갖도록 하겠습니다.